Spis treści:
W poprzednim materiale wspólnymi siłami przygotowaliśmy środowisko Visual Studio Code oraz uruchomiliśmy pierwszy przykładowy program, tym samym sprawdzając, czy wszystko działa poprawnie. W tym artykule przećwiczymy przygotowanie własnego projektu, a także opowiem wam o podstawowych zależnościach i zasadach pojawiających się w języku C.


Kup zestaw do nauki programowania z Raspberry Pi Pico W i skorzystaj z kursu dostępnego na Blog Botland!
W zestawie: moduł Raspberry Pi Pico W, płytka stykowa, przewody, diody LED, rezystory, przyciski, fotorezystory, cyfrowe czujniki światła, temperatury, wilgotności i ciśnienia, wyświetlacz OLED i przewód USB-microUSB.
Spis treści:
- Raspberry Pi Pico – #1 – zaczynamy
- Raspberry Pi Pico – #2 – słów kilka o programowaniu
- Raspberry Pi Pico – #3 – pierwszy program
- Raspberry Pi Pico – #4 – zaczynamy programować
- Raspberry Pi Pico – #5 – pętle, zmienne i instrukcje warunkowe
- Raspberry Pi Pico – #6 – PWM, ADC i komunikacja z komputerem
- Raspberry Pi Pico – #7 – Poprawki w kodzie i własne funkcje
- Raspberry Pi Pico – #8 – Przerwania i alarmy
- Raspberry Pi Pico – #9 – Teoria wskaźników i timery
- Raspberry Pi Pico – #10 – Tablice, struktury i maszyna stanów
- Raspberry Pi Pico – #11 – Uruchomienie cyfrowego czujnika światła, czyli I2C
- Raspberry Pi Pico – #12 – Przygotowujemy bibliotekę dla cyfrowego czujnika światła 1/2
- Raspberry Pi Pico – #13 – Biblioteka dla cyfrowego czujnika światła 2/2, DMA
Przed wyruszeniem w drogę należy zebrać drużynę

Chcąc uczyć się programowania, bazując na rzeczywistych projektach, potrzebny będzie oczywiście odpowiedni sprzęt, ale bez obaw – nie musisz teraz skakać między kolejnymi artykułami i przygotowywać listę niezbędnych elektronicznych elementów. W sklepie Botland dostępny jest gotowy zestaw, zawierający wszystkie komponenty niezbędne do wykonania projektów opisanych w serii poradników o Raspberry Pi Pico.
W gotowym zestawie elementów znajdziecie:
- Raspberry Pi Pico W,
- Przewód microUSB,
- Płytkę stykową,
- Zestaw przewodów połączeniowych w trzech rodzajach,
- Zestaw diod LED w trzech kolorach,
- Zestaw najczciej stosowanych w elektronice rezystorów,
- Przyciski Tact Switch,
- Fotorezystory,
- Cyfrowy czujnik światła,
- Cyfrowy czujnik wilgotności, temperatury i ciśnienia,
- Wyświetlacz OLED.
Całkiem nowy blink LED, tworzenie projektu

Poprzednio uruchomiony kod pochodził z dołączonego przez Raspberry Pi Fundation przykładu nazwanego po prostu blink. Program ten synchronicznie włączał i wyłączał diodę LED podłączoną do Raspberry Pi Pico W. Projekty typu blink są bardzo często spotykane we wszelkich poradnikach programistycznych opartych na niewielkich platformach sprzętowych. Dlatego ja również pokaże wam jak własnoręcznie napisać tego typu program, ale w nieco bardziej rozbudowanej odsłonie, bo wykorzystamy tutaj nieco większą ilość świecących diod. Na początek przygotujmy jednak potrzebny sprzęt. Do RPI Pico W podłączona była do tej pory tylko jedna, zielona dioda LED połączona z wyprowadzeniem GP0. Kolejne dwie diody należy podłączyć do następnych w kolejności pinów, czyli GP1 i GP2, które znajdują się tuż obok. Nie zapomnijcie też o rezystorach, których wartość wynosi 330 Ω. Jak możecie zauważyć na fotografii powyżej, zmieniłem nieco ułożenie pierwszej diody, tak aby katody wszystkich świecących elementów połączone były magistralą oznaczoną niebieskim kolorem (-).
Gdy obwód do przyszłych eksperymentów jest już gotowy, możemy wrócić do VSC i spróbować przygotować własny projekt, którego zadaniem będzie sterowanie trzema diodami LED. Jednak zanim do tego przejdziemy, wyjaśnić trzeba kilka kwestii organizacyjnych.
Domyślnie pod Visual Studio Code podpięty jest folder pico-examples, zawierający przykłady udostępnione przez Raspberry Pi Fundation. Jeśli chcemy przygotowywać własne projekty, warto byłoby przygotować osobne miejsce na dysku lub skorzystać, ze wspomnianego folderu z przykładami. Nic nie stoi na przeszkodzie, aby właśnie tam umieszczać nasze przyszłe projekty. Poza tym pico-examples to miejsce, do którego po prostu warto zaglądać, przykładowych programów jest tu naprawdę wiele i przygotowując własne kody, można posiłkować się umieszczonymi tam informacjami.
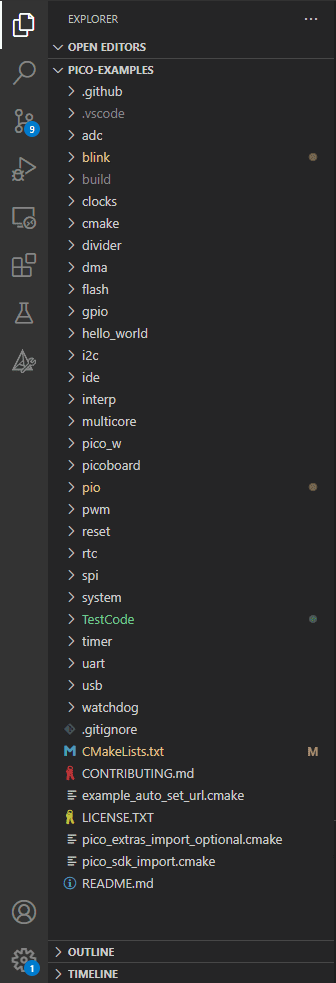
Strukturę folderu pico-examples zobaczyć możecie na obrazku obok, ale też na ekranie własnych komputerów. Plików i folderów wewnątrz jest całkiem sporo i każdy z nich pełni inną funkcję. Na początek przyjrzyjmy się wyjątkom, które nie są projektami. Foldery takie jak: .github, .vscode, i cmake związane są z organizacją całej przestrzeni. Pierwszy z nich wynika z faktu, że całość pobrana została zdalnie z serwisu GitHub, .vscode związany jest ze środowiskiem Visual Studio Code, które przechowuje tam istotne dla siebie informacje, natomiast w cmake umieszczono pliki związane z procesem kompilacji.
W pico-examples znalazło się też kilka osobnych plików, z których większość nie będzie dla nas interesująca, ponieważ zawiera informacje o konfiguracji folderu czy też licencji. Na ten moment jedynym plikiem, któremu poświęcimy nico więcej uwagi, będzie CMakeLists.txt. W jego wnętrzu znajduje się lista projektów umieszczonych w pico-examples, którą będziemy stopniowo rozbudowywać, dodając do niej własne konstrukcje. Skoro o projektach mowa, to jest ich całkiem sporo, umieszczono je w osobnych folderach, z których niektóre kryją kolejne foldery. Dla przykładu we wnętrzu adc znalazło się aż siedem projektów związanych z tym typem funkcjonalności. Ostatnim folderem, na który musimy zwrócić uwagę jest build, skorzystaliśmy już z niego w poprzednim artykule, kopiując plik .uf2. To właśnie tam znajdują się wszystkie wynikowe pliki kompilacji, zlokalizowane w konkretnych folderach, zgodnych nazwą z określeniem projektu.
Czas przejść do stworzenia w VSC naszego pierwszego projektu. Będzie to rozbudowana wersja klasycznego blinka operująca na trzech diodach LED. Na początek trzeba oczywiście wymyślić nazwę projektu, która będzie też nazwą folderu, w którym umieszczone będą nasze pliki. Musicie wiedzieć, że nazewnictwo również opiera się na pewnych zasadach. Nazwy projektów powinny być proste, najlepiej jest korzystać z określeń w języku angielskim, nie wolno korzystać z polskich znaków oraz znaków specjalnych. Projekt rozbudowanego migania diodą można nazwać po prostu jako expanded blink, ale co ważne sam styl zapisu również ma pewne znaczenie i dobrze oddaje je tekst poniżej, który zobaczyłem kiedyś na pewnym forum.
IfYouLikeReadingStuffLikeThisThenUseCamelCase.
if_you_like_reading_stuff_like_this_then_use_snake_case.
Tak więc nasz projekt zapisać możemy jako ExpandedBlink lub expanded_blink. Którą z wersji wybierzecie, zależy od was, ja zdecydowałem się na expanded_blink, ze względu na to, że w pico-examples projekty zapisywane są zgodnie z tą konwencją.
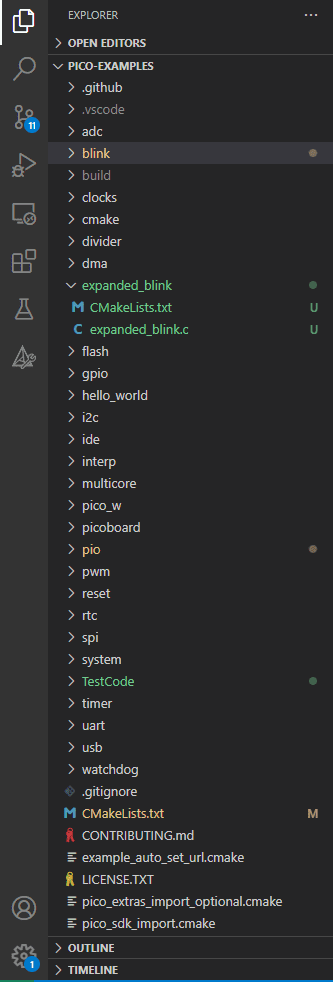
Każdy sposób zapisu jest dobry, na obrazie powyżej zauważyć możecie też folder TestCode, który jak sama nazwa wskazuje, był formą testu, przed pisaniem artykułów i jak widać, odruchowo nazwałem go zgodnie z CamelCase.
Najeżdżając na obszar Explorera, zauważyć można pojawiające się przy pico-examplec piktogramy umożliwiające tworzenie nowych plików i folderów. Tym sposobem należy wygenerować folder expanded_blink i w jego wnętrzu dodać dwa pliki: expanded_blink.c oraz CMakeLists.txt. W pierwszym z nich pisać będziemy kod w języku C, natomiast plik tekstowy zawierać będzie informacje odnoszące się do procesu kompilacji. Jeśli w waszym przypadku, oba pliki po utworzeniu zaznaczone będą na czerwono, to nie ma się czego obawiać. Na ten moment dokonaliśmy brutalnej ingerencji w strukturę folderu pico-examples i, aby nadać prawną moc zmianą należy nieco zmodyfikować plik CMakeLists.txt odnoszący się do całego pico-examples. Znajdziecie go w dolnej części widoku eksploratora plików.
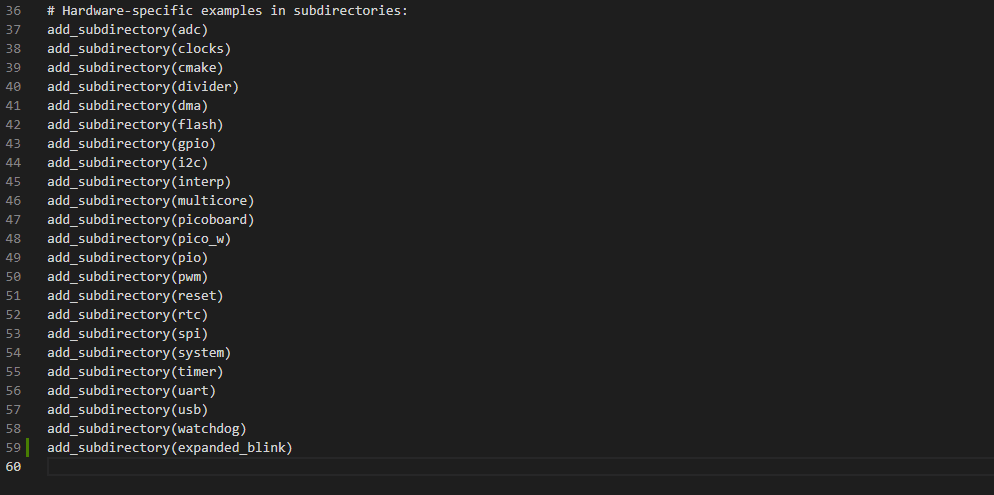
Aby nasz nowy folder, a tym samym projekt expended_blink, został zaakceptowany, musimy dodać go w pliku CMakeLists.txt. Na jego końcu możecie zobaczyć listę, na której w nawiasach wypisane zostały nazwy wszystkie przykładowych projektów. Na jej końcu dodajemy:
add_ subdirectory(expanded_blink)
Po modyfikacji plik możemy zapisać, po chwili folder pico-examples zostanie przeładowany, a dodane chwilę wcześniej pliki zaświecą się na zielono. Oznacza to, że udało nam się dodać do pico-examples nowy projekt. Oczywiście na ten moment jest on pusty, ale już za chwilę się to zmieni.
Przygotowanie kodu programu
Program, który sterować będzie naszymi świecącymi elementami, zaczynamy od pustego skryptu. Jak już wcześniej wspominałem, każdy realizowany przez mikrokontroler, procesor czy dowolną inną maszynę cyfrową program składa się z zapisanych kolejno instrukcji. Programista tworzy kod, który wykonywany jest krok po kroku, czy w takim razie pisać będziemy po prostu kod instrukcja po instrukcji, nie do końca. Byłoby tak, gdybyśmy chcieli napisać program w kodzie maszynowy, byłoby to jednak niezwykle skomplikowane. Pod tym względem język C jest prostszy i bardziej intuicyjny, innymi słowy przystosowany jest bardziej dla człowieka niż maszyny.
//comment
//program area before main function
int main(){
/*lengthy comment,
here we will place
single commands*/
}
Obszar programu możemy na początek podzielić na dwie części, to co znajduje się ponad funkcją main oraz to, co umieszczono w jej wnętrzu. Na początek zajmijmy się tą drugą, w języku C wszystkie instrukcje, które chcemy wykonać umieszczane są w funkcji main. Funkcja to nic innego jak swego rodzaju polecenie, które podczas kompilacji przekształcane jest w zbiór rozkazów maszynowych, przyjmujących postaci zer i jedynek zapisanych w pamięci. Funkcje mogą mieć postać pojedynczego polecenia lub też zbioru poleceń. Warto wiedzieć też, że funkcje możemy napisać samodzielnie, dość łatwo jest wyobrazić sobie skrypt, który co jakiś czas niezależnie od czynników zewnętrznych realizuje to samo zadanie. Zamiast pisać niezwykle rozbudowany kod, można pewne stałe elementy programu zamknąć w ramy funkcji, która wywoływana jest co jakiś czas, na zasadzie wskazania „teraz wykonaj ten fragment kodu i wróć do głównego zadania”. Funkcja main jest właśnie czymś takim, jest główną funkcją programu, wewnątrz, której umieszczać będziemy inne polecenia.
Przed słowem kluczowym main umieszczone zostało tajemnicze int, jest to jeden z podstawowych typów danych w języku C, a jego umieszczenie wynika z faktu, że funkcje mogą otrzymywać, a także zwracać pewne dane. Dla przykładu, jeśli napisalibyśmy funkcję realizującą dodawanie dwóch liczb, to musiałaby ona przyjmować pewne argumenty, wykonywać matematyczną operację, a następnie zwracać wynik. int jest właśnie informacją, jakiego typu dane zwraca funkcja main. Tym jakie są to dane, nie będziemy się jednak teraz zajmować, ale w przyszłości wrócimy do tematu.
Przy funkcji main znalazł się też nawias, w jego wnętrzu umieszczane są dane, które funkcja może przyjąć. Mogłyby to być wspomniane wyżej argumenty dla operacji dodawania. W tym przypadku jednak main nie przyjmuje żadnych danych, dlatego nawias jest pusty.
Poza zwyczajnym nawiasem zauważyć można też nawias klamrowy. W jego obrębie umieszczane będą kolejne polecenia, które wykonać ma procesor. W powyższym przykładzie umieszczany został tam komentarz. W języku C do jego dodania służy operator „//”, wszystko, co zostanie dalej napisane, jest ignorowane przez kompilator. Jeśli chcielibyście dodać większy komentarz, rozciągnięty na kilka linijek można to zrobić dzięki konstrukcji „/* lengthy comment */”. Komentarze w kodzie pełnią rolę informacji dla czytającego kod programisty, warto je dodawać, nawet do najprostszych programów. Dobrą praktyką, którą warto jest stosować, jest komentowanie kodu w języku angielskim – nigdy nie wiemy, kto akurat będzie przyglądać się naszym programom. Warto zwrócić też uwagę na sposób formatowania kodu. Jak widzicie, długi komentarz jest lekko przesunięty, a dokładniej na początku każdej linii wstawiony jest znak tab. Zabieg taki ma za zadanie ułatwić czytanie kodu, dla kompilatora dodatkowe wcięcia nie mają żadnego znaczenia. Umowną zasadą jest stosowanie dodatkowego tabulatora w sytuacjach, gdy instrukcje umieszczone są wewnątrz funkcji, instrukcji warunkowych, pętli i innych specyficznych konstrukcji w kodzie. Jest to dość intuicyjne i z czasem na pewno wejdzie wam w nawyk. Poza tym pisząc kod w VSC, program będzie automatycznie dodawać znak tab do nowej linii, zgodnie z wcześniej napisanym poleceniem.
Jak wspomniałem, ponad funkcją main również znajduje się obszar programu, jest to specyficzne miejsce, w którym umieszczać będziemy konkretne konstrukcje takie jak stałe, definicja, deklaracje czy dyrektywy. Poznamy je z czasem, na praktycznych przykładach.
Gdy wiecie już jak pokrótce wygląda konstrukcja programu w języku C, możemy przejść do jego napisania. Jednak, aby było to możliwe, musimy określić co konkretnie robić ma nasz program. Będzie to rozbudowana wersja skryptu migającego diodą LED, także możemy przygotować program, który będzie uruchamiać kolejne diody, co określony okres, gasząc jednocześnie poprzednią. Coś na zasadzie włączenie zielonej diody, odczekanie pół sekundy, włączenie żółtej i wyłączenie zielonej, odczekanie pół sekundy, włączenie czerwonej i wyłączenie żółtej i tak dalej.
#include "pico/stdlib.h"
int main() {
gpio_init(0); //initialization of GP0, GP1 and GP2 pins
gpio_init(1);
gpio_init(2);
gpio_set_dir(0, GPIO_OUT); //setting GP0, GP1 and GP2 as outputs
gpio_set_dir(1, GPIO_OUT);
gpio_set_dir(2, GPIO_OUT);
gpio_put(0, 1); //set state 1 on pin 0
sleep_ms(500); //wait 500ms
gpio_put(0, 0); //set state 0 on pin 0
gpio_put(1, 1); //set state 1 on pin 1
sleep_ms(500);
gpio_put(1, 0);
gpio_put(2, 1);
sleep_ms(500);
gpio_put(2, 0);
sleep_ms(500);
}
Pierwszym programem, który uruchomimy, będzie ten, którego kod możecie zobaczyć powyżej. Na razie może on wyglądać nieco tajemniczo, ale już za moment, gdy wytłumaczę wam jego strukturę, wszystko stanie się jasne. Całość składa się tak naprawdę z czterech typów poleceń, powtórzonych kilkukrotnie z różnymi parametrami. Analizę zacznijmy od istoty kodu, czyli instrukcji umieszczonych we wnętrzu głównej funkcji.
Pierwsze trzy instrukcje to gpio_init, przyglądając się im, dość łatwo jest zrozumieć ich znaczenie – init to skrót od initialization, natomiast gpio oznacza general purpose input/output. Tak więc gpio_init to nic innego jak polecenie inicjalizacji portu input/output (I/O), dzięki któremu mikrokontroler przygotuje do działania konkretne wyprowadzenia zewnętrzne. O tym, które będą to wyprowadzenia, decyduje cyfra umieszczona wewnątrz nawiasu. 0, 1, 2 to porty GP0, GP1 i GP2, do których podłączyliśmy wcześniej diody LED. Warto byłoby też wskazać w jakim trybie będziemy z tych portów korzystać, aktualnie RP2040 wie tylko, że chcemy użyć trzech pinów, jednak ich przeznaczenie pozostaje tajemnicą. Aby to zmienić, należy skorzystać z gpio_set_dir, tego typu polecenie również dość łatwo rozwinąć. Znaczenie gpio już znacie, set to po prostu set, natomiast dir jest skrótem od direction. Używane w projekcie piny będą sterować diodami świecącymi, dlatego należy skonfigurować je jako wyjścia, innymi słowy układ będzie sterować tymi wyprowadzeniami, ustawiając na nich odpowiedni stan logiczny. Aby ustawić GP0, GP1 oraz GP2 jako wyjścia należy w parametrach funkcji gpio_set_dir podać informację o numerze wyprowadzenia: 0, 1, 2 oraz słowo kluczowe GPIO_OUT. Zauważcie, że wszystkie do tej pory omówione polecenia zakończone są średnikiem, taki zabieg jest celowy, ponieważ informuje on kompilator, że właśnie w tym miejscu kończy się konkretne polecenie.
Gdy wyprowadzenia są już skonfigurowane, możemy zacząć nimi sterować. Do tego celu wykorzystamy gpio_put, dzięki któremu możliwe jest ustawianie na wyjściu stanu zero lub jeden. Ten podawany jest wewnątrz nawiasu, jak drugi parametr opisany cyfrą 0 lub 1. Pierwsza cyfra w nawiasie to numer wyprowadzenia, tak więc gpio_put(0, 1); opisać możemy jako ustaw stan jeden na pinie zerowym.
Ostatnim wykorzystanym w programie poleceniem jest sleep_ms, znaczenie tej funkcji również jest dość przewidywalne. Powoduje ona po prostu wstrzymanie pracy mikrokontrolera na określony czas, w tym przypadku milisekundy, których wartość umieszczona jest w nawiasie. Cyfra 500 oznacza 500ms, czyli oczekiwane przez nas pół sekundy.
Programy w języku C wykonywane są krok po kroku, instrukcja po instrukcji. Zauważcie na początku uruchamiamy diodę podłączoną do GP0, następnie odczekujemy 500ms i w następnych krokach wyłączamy diodę, która świeciła pół sekundy, włączając w tym samym momencie kolejny element świecący. Następnie po raz drugi odczekujemy 500ms, a cykl włączenia i wyłączenia diod LED powtarza się, z tą różnicom, że teraz sterujemy pinem GP1 i GP2. W ten sposób możemy analizować programy, rozkładając kod na kolejne realizowane przez mikrokontroler kroki.
Na początku programu zobaczyć możecie też tajemniczą linijkę #include “pico/stdlib.h”. Jak już wspominałem, ponad główną funkcją programu umieszczać będziemy konkretne konstrukcje, takie jak dołączenia, w kodzie możecie zobaczyć właśnie coś takiego. Jest to bardziej informacja dla kompilatora, aniżeli część realizowanego przez chip programu. Dzięki dołączonej w kodzie bibliotece, możemy korzystać ze specyficznych funkcji i parametrów przygotowanych przez Raspberry Pi Fundation. Dla przykładu, gdy usuniemy dołączenie biblioteki stdlib, VSC zgłosi nam błąd, informujący, że coś takiego jak GPIO_OUT jest mu nieznane. To właśnie dzięki zewnętrznej bibliotece mogliśmy zadeklarować port wyjściowy właśnie w ten sposób. Wyjaśnienia wymaga też sam zapis tej dyrektywy, na początku mamy słowo kluczowe #include, następnie w podwójnym cudzysłowie umieszczona jest ścieżka do tak zwanego pliku nagłówkowego (rozszerzenie .h), w którym zapisane są prototypy funkcji, które mogą być wykorzystywane w kodzie, oczywiście, jeśli na jego początku znalazło się odpowiednie dołączenie. Zewnętrznych bibliotek, jest całkiem sporo i w kolejnych przykładach będziemy z nich korzystać praktycznie zawsze, a poza tym w przyszłości przygotujemy również własną bibliotekę.
W ten oto sposób nasz pierwszy kod jest gotowy, ale już teraz zdradzę, że nie jest to jego ostateczna forma i w dalszej części artykułu wprowadzimy w nim pewną modyfikację. Kod możecie oczywiście skopiować, ale polecam przepisać go samodzielnie. W ten sposób zdobyta wiedza przyswoi się znacznie lepiej.
Uzupełnienie pliku CMakeLists
add_executable(expanded_blink
expanded_blink.c
)
# pull in common dependencies
target_link_libraries(expanded_blink pico_stdlib)
# create map/bin/hex file etc.
pico_add_extra_outputs(expanded_blink)
Jedynym elementem, który uniemożliwia nam jeszcze uruchomienie projektu rozbudowanego blinka, jest plik CMakeLists.txt i jego zawartość, której jeszcze nie ma. Przygotowanie tak zwanych plików „make”, których zadaniem jest automatyzacja procesu kompilacji i budowania oprogramowania, może być niezwykle skomplikowanym procesem. Dlatego nie będę zbyt głęboko poruszać tego tematu, w internecie dostępnych jest całkiem sporo treści, przybliżających ogólny koncept plików „make”.
W przypadku RPI Pico CMakeLists.txt podzielony jest na trzy części. W pierwszej, dzięki poleceniu add_executable dodajemy do projektu expended_blink plik wykonywalny expended_blink.c, jeśli plików będzie więcej, a w przyszłości zdarzą się takie sytuacje należy, je tutaj umieścić. Następnie należy zaznaczyć, jakie bibliotek zostały wykorzystane w projekcie, jest to możliwe dzięki target_link_libraries, gdzie w nawiasie umieszczamy nazwę projektu oraz dołączone biblioteki. Ostatnią regułą umieszczoną w CMakeLists jest pico_add_extra_outputs, dzięki której w trakcie procesu kompilacji wygenerowane zostaną wszystkie pliki binarne.
Pierwsze uruchomienie expanded_blink
Nadszedł czas na pierwsze uruchomienie projektu expanded_blink, jeśli wszystkie pliki są zapisane, możemy przejść do zakładki CMake, z której korzystaliśmy już w poprzednim materiale. Należy tam tak jak poprzednio wybrać odpowiedni projekt w opcji Build, a następnie uruchomić kompilacje.
Gdy ta zakończy się pomyślnie, można, podobnie jak w przypadku pierwszego projektu blink, wrzucić plik expended_blink.uf2 na RPI-RP2. Pamiętajcie o wciśnięciu przycisku na płytce w momencie jej podłączania, tak aby Raspberry Pi Pico W uruchomiło się w trybie programowania.
Po zapisaniu danych powinniście zobaczyć efekt taki jak na filmie powyżej – każda z diod LED zaświeci się kolejno na pół sekundy, po czy wszystkie zgasną. Jednak czy takiego efektu oczekiwaliśmy? No nie do końca. Cała sekwencja powinna wykonać się ponownie i ponownie, czy w takim razie przygotowany kod jest obarczony jakimś błędem? Nie, wszystko wykonane zostało zgodnie z planem, a kod działa poprawnie. Przyjrzyjcie się napisanemu programowi, inicjalizujemy trzy piny, wybieramy ich funkcjonalność, a następnie kilkoma poleceniami ustawiającymi konkretny stan logiczny i wstrzymującymi pracę RP2040 sterujemy diodami LED. Jednak co dzieje się, gdy układ wykona ostatnią instrukcję sleep_ms(500);? Prawidłowa odpowiedź to nic, program został wykonany, chip nie ma pojęcia, że z naszej perspektywy warto by cały proces włączania i wyłączania diod powtórzyć.
Niekończące się efekty świetlne
#include "pico/stdlib.h"
int main() {
gpio_init(0); //initialization of GP0, GP1 and GP2 pins
gpio_init(1);
gpio_init(2);
gpio_set_dir(0, GPIO_OUT); //setting GP0, GP1 and GP2 as outputs
gpio_set_dir(1, GPIO_OUT);
gpio_set_dir(2, GPIO_OUT);
while (true) { //infinite while loop
gpio_put(0, 1);
sleep_ms(500);
gpio_put(0, 0);
gpio_put(1, 1);
sleep_ms(500);
gpio_put(1, 0);
gpio_put(2, 1);
sleep_ms(500);
gpio_put(2, 0);
sleep_ms(500);
}
}
Jeśli chcemy, aby RP2040 przez cały czas, synchronicznie uruchamiał i wygaszał diody, musimy w jakiś sposób zapętlić część kodu realizującą to zadanie. Pierwszych dwóch zbiorów poleceń odpowiedzialnych za konfigurację portów i nie ma sensu wykonywać wielokrotnie, wyprowadzenia raz skonfigurowane jako wyjścia, pozostaną już w takim stanie. Aby kod sterujący diodami LED mógł wykonywać się w nieskończoność, a w zasadzie do czasu wyłączenia zasilania musimy wrzucić go w pętlę. W języku C pętle to specyficzne konstrukcje, które pozwalają umieszczony w nich kod wykonywać wielokrotnie. Poza tym pętle mogą być skojarzone z pewnymi warunkami, tym samy możemy sterować ich wykonywaniem, pętla może wykonać się tylko kilkukrotnie, może nie wykonać się wcale lub może wykonywać się w nieskończoność.
W naszym kodzie skorzystamy z pętli while, która działa do momentu, gdy spełniony jest warunek umieszczony w nawiasie. Innymi słowy, kod umieszczony wewnątrz pętli będzie wykonywany tak długo, puki warunek umieszczony w nawiasie będzie spełniony. Gdy kod z wnętrza pętli zostanie wykonany, układ wraca do jej początku, wykonując go po raz kolejny.
Coś takiego jak nieskończona pętla jest w programowaniu spotykane nad wyraz często. Zazwyczaj chcemy, aby program realizowany był cały czas, niezależnie czy tylko sterujemy diodami świecącymi, czy też dla przykładu odczytujemy dane z czujnika temperatury, a wartość wyświetlamy na wyświetlaczu. Kod musi być wykonywany non stop, w innym przypadku temperatura odczytana byłaby tylko raz i na ekranie widoczny byłby tylko jeden odczyt.
W takim razie co należy umieścić w warunku pętli while, aby ta wykonywana była w nieskończoność? Odpowiedź jest prosta – prawdę, czyli po prostu true. W języku C coś takiego jak true, możemy traktować właśnie jako zawsze spełniony warunek. Tym sposobem można stworzyć zawsze wykonującą się pętle. Oczywiście w nawiasie tworzyć możemy też bardziej rozbudowane warunki, ale tym zajmiemy się w kolejnych materiałach.
Po kompilacji i wrzuceniu na Raspberry Pi Pico W nowego pliku extended_blink.uf2 możemy zobaczyć, że tym razem diody włączane i wyłączane są wielokrotnie, czyli nasza nieskończona pętla while działa poprawnie. Na tym zakończymy projekt rozbudowanego programu sterującego diodami LED, ale zachęcam was do eksperymentów. Możecie spróbować zmienić wyprowadzenia, do których podłączone są świecące elementy, zmienić wartości czasu, czy też całkowicie zmodyfikować funkcje gpio_put, tak aby teraz diody były synchronicznie wyłączane, a nie włączane. Dzięki tym kilku instrukcjom, które opisałem w tym artykule, można przygotować całkiem ciekawe efekty świetlne. Podsumowując, nie obawiajcie się tworzyć własnych projektów, to właśnie dzięki nim tak naprawdę uczycie się programować.
Problem sleep_ms i innych funkcji blokujących

Na koniec chciałbym opowiedzieć wam o czymś jeszcze. W dzisiejszym projekcie wykorzystaliśmy funkcję sleep_ms, która podobnie jak inne, tak zwane funkcje blokujące jest z pewnych względów problematyczna. Na ten moment może wydawać się ona niezwykle praktyczna i użyteczna, wszakże pozwala w prosty sposób wstrzymać działanie programu na określoną ilość czasu, ale niestety w tym wstrzymaniu leży jej największy problem. Co dzieje się z układem RP2040, gdy natrafi on na polecenie sleep_ms? Chip czeka, aż minie zadeklarowany czas i w tym momencie nie wykonuje żadnych zadań, a co gorsze nie jest w stanie reagować na czynniki zewnętrzne. Aktualnie może wydawać się to mało znaczące, ale gdy poznamy coś takiego jak przerwania, okaże się, że wstrzymywanie programu jest wielce niewskazane. Poza tym, gdy mikrokontroler po prostu czeka, jego moc jest marnowana.
Chciałbym, abyście już teraz zapamiętali, że wszelkie funkcje blokujące, mimo że kuszące są w programowaniu niepożądane. Istnieją optymalniejsze sposoby na pozorne „wstrzymanie” działania programu, które oczywiście w przyszłości poznamy. Funkcja sleep_ms nie należy do poleceń zakazanych, ale jeśli zdecydujemy się ją umieścić w kodzie, trzeba to dobrze przemyśleć i mieć świadomość jej ograniczeń.
Kilka słów na koniec…
Za nami pierwszy stworzony od zera projekt. Uruchomiliśmy trzy diody LED i mam nadzieję, że po poznaniu kodu wprowadziliście do niego pewne zmiany, innymi słowy eksperymentowaliście, bo to właśnie zabawa z kodem jest esencją programowania. Moim zadaniem jest tylko opisać kilka prostych funkcji, to jak działają, co powodują i jak użyć ich w praktycznych przykładach, ale to w prototypowaniu leży magia nauki. Poza tym opowiedziałem wam nieco o plikach konfiguracyjnych make, a także poznaliśmy pierwszy rodzaj pętli spotykanej w programowaniu. Na koniec zaś poznaliśmy problemy tak zwanych funkcji blokujących. W kolejnych materiałach czeka was wiele nowości, poznamy kolejne rodzaje pętli i funkcje warunkowe, a wszystko to na praktycznych projektach.
Źródła:
- https://datasheets.raspberrypi.com/rp2040/rp2040-datasheet.pdf
- https://datasheets.raspberrypi.com/picow/pico-w-datasheet.pdf
- https://www.raspberrypi.com/products/rp2040/
- https://www.raspberrypi.com/documentation/microcontrollers/raspberry-pi-pico.html
Jak oceniasz ten wpis blogowy?
Kliknij gwiazdkę, aby go ocenić!
Średnia ocena: 4.9 / 5. Liczba głosów: 31
Jak dotąd brak głosów! Bądź pierwszą osobą, która oceni ten wpis.









