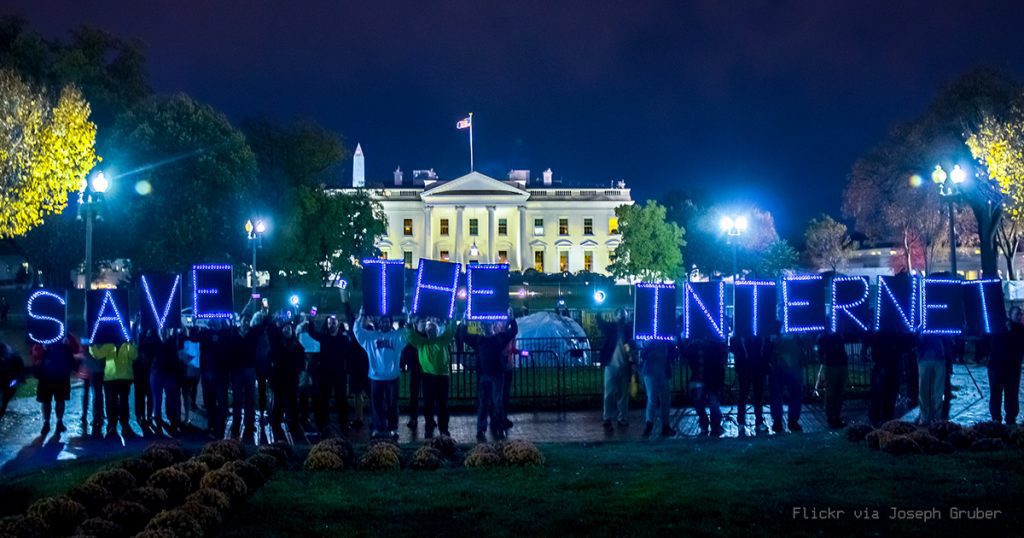Spis treści:

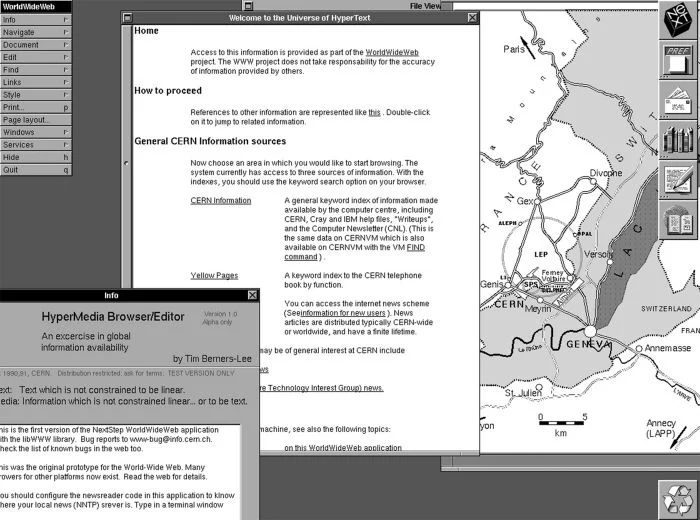
Źródło: sciencealert.com

"Web 2.0 to rewolucja biznesowa w przemyśle branży komputerowej spowodowana przejściem do Internetu jako platformy, oraz próba zrozumienia zasad sukcesu na tej nowej platformie. Główną z tych zasad jest to: buduj aplikacje, które wykorzystują efekty sieciowe, a im będą lepsze, tym więcej osób będzie ich używać."

Tim O'Reilly
wypowiedź z 2006 roku na oficjalnej witrynie autora