Spis treści:
Współczesne duże modele językowe (LLM) całkiem sprawnie udają ludzi. Oczywiście w dość ograniczonej sferze, nie są to przecież humanoidalne roboty rodem z filmów science fiction, ale trzeba przyznać, że generowane przez przykładowo chatGPT odpowiedzi mogą wydawać się ludzkie. Dodatkowo, gdy dodamy do tego modulowany sztucznie głos, ludzki umysł może wpaść w dysonans poznawczy. Komputer „mówi”, a jego wypowiedzi nie cechuje tylko surowa forma i logika, powszechnym jest, że sztucznie wygenerowana wypowiedź, ma znacznie bardziej rozbudowaną formę. Dodatkowa humorystyczna wstawka, refleksja nad pytaniem, czy nawet coś, co moglibyśmy nazwać uczuciami maszyny. Wszystko to sprawia, że modele językowe wydają się bardziej ludzkie, choć w rzeczywistości ich działanie sprowadza się głównie do przewidywania kolejnego słowa, z którego budowane są większe zdania.
Jednak tym razem nie będziemy się skupiać na samym działaniu sztucznej inteligencji, o tym przygotowałem już kiedyś materiał „Czy naprawdę wiemy, jak działa sztuczna inteligencja?”. W tym artykule opowiem wam nieco o historii i rozwoju modeli językowych, z których tak chętnie korzystają codziennie tysiące użytkowników.
Od fikcji do rzeczywistości
„What we want is a machine that can learn from experience,” and that the „possibility of letting the machine alter its own instructions provides the mechanism for this.”
Alan M. Turin 1947.
Chcąc opowiedzieć historię współczesnych modeli LLM, musimy cofnąć się mniej więcej do połowy XX wieku. Koncepcja sztucznej inteligencji nie jest niczym nowym, ludziom od wieków znana jest koncepcja maszyny, która mogłaby się „uczyć”. Jednak dopiero na przełomie lat 40. i 50. XX wieku wizje kreowane na potrzeby tekstów kultury zaczęły wydawać się nieco bardziej przystępne. Jest to zasługa pierwszego pokolenia naukowców, które zajęło się tematem AI na poważnie. Jednym z nich był między innymi brytyjski uczony Alan Turing. Jego wkład w budowanie społecznej świadomości związanej ze sztuczną inteligencja jest powszechnie znany, mowa tutaj między innymi o zaprezentowanym w 1947 roku w Londynie wykładzie, którego istotą była teza, że ludzkość powinna dążyć do budowy systemów, które mógłby modyfikować same siebie, czy też opublikowana trzy lata później praca „Computing Machinery and Intelligence”, w której przedstawiono matematyczne założenia funkcjonowania sztucznego umysłu. Jednak mimo zapału naukowców do budowy inteligentnych maszyn i dość dobrej bazie teoretycznych założeń problemem okazała się ówczesna technologia. Temat ten poruszyłem szerzej w artykule „Technologiczne ograniczenia sztucznej inteligencji” dlatego tym pominę ten jakże ciekawy okres historii i przejdziemy od razu do aspektów związanych z budową modeli językowych.
Model językowy, czyli co?
Jednym z pierwszych zastosowań zauważonym przez naukowców, do których można było zaprząc cyfrowe sprzęty, było tłumaczenie maszynowe. Z dzisiejszej perspektywy wydaje się to dość prymitywne, wszakże coś takiego jak „tłumacz” z powodzeniem funkcjonuje już od wielu lat. Jednak nietrudno wyobrazić sobie, że ponad pół wieku temu myśl o maszynie tłumaczącej tekst naprawdę rozpalała umysł. Pierwsze próby wykorzystania wczesnych komputerów do tego typu zadań urzeczywistniły się podczas II Wojny Światowej. Zarówno jedna, jak i druga strona konfliktu prowadziła badania nad tłumaczeniem maszynowym i było to rozwinięcie prac, związanych z łamaniem kodów i szyfrów przeciwnika.
Po zakończeniu II Wojny Światowej prace nad modelami językowymi przeniosły się z państwowych laboratoriów do prywatnych firm i uniwersytetów zlokalizowanych głównie w Stanach Zjednoczonych. Również tym razem to konflikt napędzał badania nad pierwszymi tłumaczami, nie była to jednak otwarta, zbrojna konfrontacja a rywalizacja dwóch największych mocarstw, czyli USA i Związku Radzieckiego, określana później jako zimna wojna. Jednym z największych projektów w powojennej rzeczywistości były badania nad autonomicznym algorytmem, który tłumaczyłby zwroty w języku rosyjskim na angielski. Przedsięwzięcie to realizowało IBM we współpracy z Uniwersytetem Georgtown.
Jednak mimo niezwykle uzdolnionej grupy naukowców i dość sporych nakładów finansowych, projekt ten skończył się porażką. Utrwaliło to przekonanie, że zadanie przetwarzania ludzkiego języka cechującego się niezwykłą złożonością i zawiłością nie będzie czymś prostym w realizacji.
Gdzie kończą się reguły…
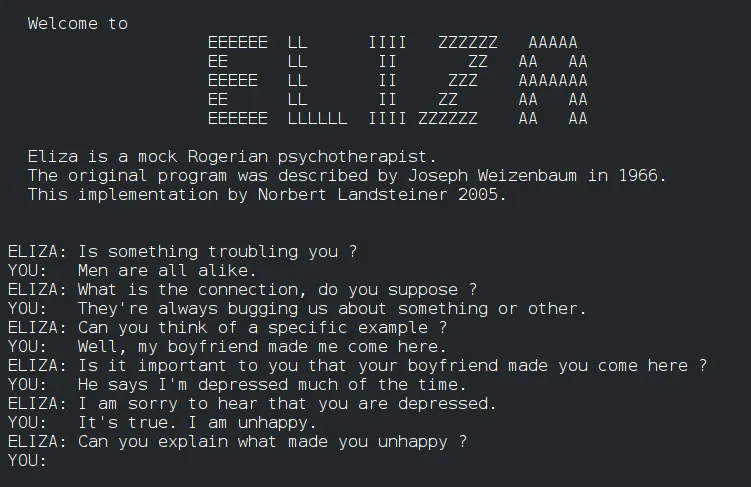
Kamieniem milowym w rozwoju modeli językowych było pojawienie się pierwszego na świecie chatbota. Eliza, bo pod taką nazwą funkcjonował ten projekt, opracowany przez badacza z MIT Josepha Weizenbauma w 1966 roku był to dość prostym programem symulującym rozmowę. Algorytm Elizy bazował na rozpoznawaniu wzorców w danych wprowadzonych przez użytkownika i generowania na ich podstawie odpowiedzi i pytań. Reguł, na których bazowała Eliza nie było zbyt wiele, przez co możliwości chatbota były dość ograniczone, jednak choć projektowi daleko było do doskonałości stanowił on początek poważnych badań nad przetwarzaniem języka naturalnego i nie tylko jego tłumaczenia, ale też rozumienia.
Z projektem tym wiąże się też pewna ciekawostka. W psychologii znane jest coś takiego jak „Eliza Effect”. Wzięło się to z faktu, że osoby, którym po raz pierwszy pozwolono „porozmawiać” z komputerowym modelem językowym, były wręcz oczarowane. Mimo że Eliza odpowiadała w dość przewidywalny i ograniczony sposób, zauważono, że większość osób miała tendencję do nieświadomego zakładania, że komputer zachowuje się jak człowiek przedstawiając własne przemyślenia, czy nawet emocje.
W kolejnych latach pojawił się też SHRDLU, czyli model również opracowany w MIT, ale przez Terrego Winograda. Projekt ten, choć również ograniczony, zwłaszcza jeśli chodzi o przekazywane komputerowi polecenia, te składane były z wcześniej przygotowanych fraz, wyróżniał się biegłością w budowie odpowiedzi. Program w dość naturalny sposób łączył rzeczowniki, czasowniki i przymiotniki, przez co generowany tekst wydawał się jeszcze bardziej ludzki.
Przewidywania i prawdopodobieństwa
Znacząca zmiana w podejściu do konstruowania modeli językowych następuje w latach 90. XX wieku. Zamiast polegać na sztywno ustalonych wzorcach i regułach badacze skupili się na rozwiązaniach zwanych modelami statystycznymi. Ich działanie polegało przede wszystkim na analizowaniu i przewidywaniu kolejnego występującego w tekście słowa. Dzięki temu, model mógł być bardziej elastyczny i nieprzewidywalny w pozytywnym tego słowa znaczeniu. Przetwarzanie tekstu w ten sposób pozwalało znacznie lepiej określić ogólny sens całej wypowiedzi, aniżeli znaczenie poszczególnych słów.
Modele statystyczne, choć elastyczne i obiecujące, były problematyczne pod względem zapotrzebowania na dane. Program nie mógł działać w oparciu o magiczną zasadę prawdopodobieństwa tak po prostu, musiał wiedzieć wcześniej jakie słowa występują po sobie najczęściej jednocześnie sprawdzając ogólny sens wypowiedzi. Dla przykładu w zadaniu „Volkswagen jest niemieckim koncernem…” oczywistym jest, że ostatnim słowem będzie „motoryzacyjnym”, ale typów koncernów jest wiele, dlatego algorytm musi połączyć słowa kluczowe „Volkswagen”, „niemiecki” i na ich podstawie wygenerować odpowiedź. Aby było to możliwe, naukowcy musieli nakarmić algorytm wcześniej sprawdzonymi i wyselekcjonowanymi informacjami.
W tamtych latach przełomowymi modelami były konstrukcje n-gram. Oszacowywały on prawdopodobieństwo kolejnego słowa, bazując na matematycznych wzorach, jednocześnie analizując sens wcześniejszego tekstu. Tak jak poprzednie modele urzeczywistniły wizję łączenia ludzkich słów przez maszyny, tak n-gram pozwolił znacznie lepiej wychwycić subtelności języka.
Lata 90. są też czasem pojawienia się pierwszych sieci neuronowych i modeli głębokiego uczenia. Choć na początku wykorzystywano je przede wszystkim do przetwarzaniu obrazów, to z czasem uczeni zauważyli, że te całkiem sprawnie radzą sobie z generowaniem tekstu. Niestety podobnie jak w modelach statystycznych problemem była skala. Projekty oparte o sieci neuronowe generowały dość dobre krótkie teksty, jednak miały znaczący problem z dłuższymi formami i zachowaniem ich spójności. Jednym z przykładów tego typu modeli były Neural Network Language Model (RNNLM) oraz Latent Semantic Analysis (LSA).
Współczesne modele językowe
Przez lata dominującymi były modele statystyczne, jak i te bazujące na sieciach neuronowych, a na kolejny krok milowy w tej dziedzinie musieliśmy czekać do 2017 roku. To wówczas światło dzienne ujrzała praca „Attention is All You Need”, w której zaproponowano wykorzystanie nowatorskiego systemu uwagi. Założenie było dość proste: skoro modele generują kolejne słowa na bazie tych wykorzystanych wcześniej, to umożliwmy im też ich modyfikowanie. Dzięki temu algorytm będzie mógł wrócić do wcześniej stworzonego tekstu, aby dostosować go w taki sposób, aby pasował do kolejnych fraz.
Podejście to zrewolucjonizowało sposób, w jaki działały modele językowe, zwiększając znacznie jakość generowanych odpowiedzi, jak i poprawiając specjalizacje algorytmu. Ten mógł być od teraz znacznie lepiej wykorzystywany w konkretnych typach zadań, czego efektem było powstanie modeli takich jak: BERT, GPT, T5 czy RoBERTa.
Punktem zwrotnym okazało się też wprowadzenie niedługo później przez OpenAI modelu GPT-2. Pod względem działania bazował on na swoim poprzedniku, ale jednocześnie oszałamiał skalą. Dzięki temu generowane teksty były jeszcze bardziej doskonałe, choć jednocześnie obarczone pewnym problemem. Obszerność wczesnych iteracji chataGPT sprawiła, że ten miał skłonności do konfabulacji i generowania nieprawdziwych odpowiedzi, co swoją drogą nadal jest sporym problemem modeli językowych.
W ten sposób docieramy do aktualnie stosowanych algorytmów GPT-3, GPT-4, BERT 2, Copilot czy też Jurassic-1. Modele te imponują swoją złożonością – GPT-4 jest około pięć razy większy od swojego poprzednika i trzy tysiące razy większy od oryginalnego modelu BERT. Ilość danych, które wykorzystano przy etapie tworzenia, również jest ogromna, poza tym wiele z nich ma dostęp do internetu, przez co odpowiedzi generowane są na najświeższej wersji danych. Pod względem działania bazują one na pracy „Attention is All You Need”, jednocześnie implementując ciekawe rozwiązania, takie jak generowanie odpowiedzi na podstawie własnych wcześniej stworzonych tekstów, czy też wzorowaniu się na już powstałych modelach.
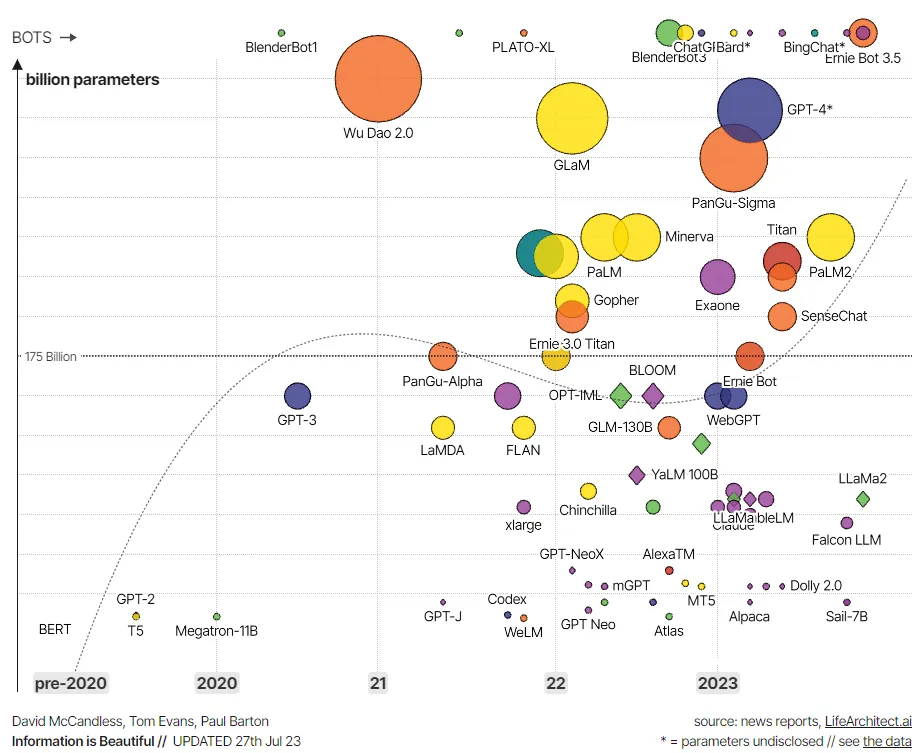
Historia modeli językowych jest sztandarowym przykładem dążenia do lepszego zrozumienia języka naturalnego. Od potrzeby tłumaczenia tekstów, przez proste modele bazujące na z góry ustalonych regułach, po ogromne i otwarte algorytmy mogące modyfikować swoje własne odpowiedzi. Mimo że już teraz chatGPT zaskakuje swoim działaniem i to w pozytywny sposób to wydaje się, że nadal jesteśmy na początku drogi. Na horyzoncie zauważyć możemy problemy z bezpieczeństwem, halucynacjami (generowanie nieprawdziwych odpowiedzi) czy też zapotrzebowaniem na energię i moc obliczeniową. Jednak niezależnie od tego wydaje się, że przyszłość będzie ciekawa.
Źródła:
- https://www.dataversity.net/a-brief-history-of-large-language-models/
- https://en.wikipedia.org/wiki/Language_model
- https://medium.com/@adria.cabello/the-evolution-of-language-models-a-journey-through-time-3179f72ae7eb
- https://lifearchitect.ai/timeline/
- https://en.wikipedia.org/wiki/Hidden_Markov_model
- https://en.wikipedia.org/wiki/N-gram
- https://medium.com/@kirudang/language-model-history-before-and-after-transformer-the-ai-revolution-bedc7948a130
- https://www.youtube.com/watch?v=8fX3rOjTloc
- https://toloka.ai/blog/history-of-llms/
Jak oceniasz ten wpis blogowy?
Kliknij gwiazdkę, aby go ocenić!
Średnia ocena: 5 / 5. Liczba głosów: 1
Jak dotąd brak głosów! Bądź pierwszą osobą, która oceni ten wpis.










