Spis treści:
Z dnia na dzień sztuczna inteligencja staje się coraz bardziej powszechna. Zaczęło się od prostych algorytmów analizujących obrazy i modeli językowych, a skończyło na sytuacji, w której niemal każde urządzenie musi mieć coś wspólnego z AI. Producenci sprzętów elektronicznych wszelkiego rodzaju prześcigają się, w co raz to nowszych marketingowych hasłach informujących, że to właśnie ich sprzęt jest bardziej inteligentny. Wydaje się, że już za moment sztuczna inteligencja będzie robić niemal wszystko – odpisze na maila, wymyśli życzenia urodzinowe, a na koniec zaproponuje co zjeść na kolacje. Pozostaje jednak pytanie, jaką rolę odgrywać będzie w tym wszystkim człowiek? Bo chyba tylko konsumenta kolejnej reklamy wyświetlanej przed wygenerowanymi przed AI treściami (nadal zastanawiam się, dlaczego ChatGPT nie ma jeszcze zaimplementowanych reklam).
Każdy chce mieć swoje własne AI do tego stopnia, że pewna firma postanowiła inaczej rozwijać skrót AI i od teraz nie jest to już artificial innteigence tylko Apple Inteligence. Można by powiedzieć, że „Moje sztuczna inteligencja jest mojsza niż twojsza”, jeśli chcielibyśmy zastosować filmowe porównanie. Jednak co by nie mówić AI jest pewną szansą. Nadeszły czasy, w których dostępna moc obliczeniowa pozwoliła uruchamiać naprawdę rozbudowane algorytmy, które nie raz okazały się przydatne. Jednym z przykładów może być sytuacja, która wydarzyła się jakiś czas temu w Stanach Zjednoczonych. Uruchomiony pilotażowo program, w którym to sztuczna inteligencja miała analizować zdjęcia rentgenowskie pacjentów, pozwolił wykryć wczesny etap nowotworu jednej z notabene pielęgniarek. W sytuacji, gdy lekarze nie zauważył żadnych objawów. Jest całkiem sporo obszarów, w których rzeczywiście AI radzi sobie znacznie lepiej niż człowiek i osobiście uważam, że właśnie tam przede wszystkim powinna być angażowana ta technologia, a niekoniecznie do generowania odpowiedzi na maile, choć zapewne zwycięży wygoda i konsumpcjonizm.
Jak każde przedsięwzięcie, tak i AI ma swoje jasne i ciemne strony, ale dzisiaj chciałbym nieco bardziej skupić się na tych drugich. Zdarzają się głosy z branży mówiące, że z tym AI to nie jest wcale tak kolorowo, głównie przez fakt, że nie do końca rozumiemy, jak sztuczna inteligencja działa. Czy jest tak w rzeczywistości? Sprawdźmy to!
Od marzeń do rzeczywistości

Inteligencja czy iluzja?
Koncepcja sztucznej inteligencji nie jest niczym nowym. Już w pierwszej połowie XX wieku naukowcy snuli teorię o uczących się maszynach. Jednak każde teoretyczne rozważania weryfikowane były przez stan ówczesnej techniki. Początkowo nie było fizycznych możliwości budowy jakiegokolwiek systemu, który mógłby być opisany jako inteligentny. Światełko w tunelu pojawiło się wraz z rozwojem branży komputerowej, jednak pierwsze maszyny tego typu również były zbyt prymitywne, na kamień milowy sztucznej inteligencji przyszło nam poczekać dość długo, choć nie znaczy to, że w tej dziedzinie nie działo się nic ciekawego.
Lata 50. i 60. To czas dynamicznego rozwoju koncepcji AI. Pojawia się praca Alana Turinga o tytule „Computing Machinery and Intelligence”, w której sformułowano teoretyczne podstawy sztucznej inteligencji. Powstają pierwsze uczące się algorytmy oraz modele językowe, ale mimo optymizmu ludzi takich jak Marvin Minsky, który przewidywał, powstanie inteligentnych maszyn w ciągu kilku lat, ograniczenia technologiczne okazują się zbyt wielką przeszkodą. Kazus technologicznych ograniczeń AI był motywem przewodnim jednego z moich poprzednich artykułów „Technologiczne ograniczenia sztucznej inteligencji”.
Paradoksalnie, pomimo okresowego spadku zainteresowania i ograniczonego finansowania, które cechowało lata 70. i 80. XX wieku AI nadal rozwijano w zaciszach laboratorium. Kluczowym momentem okazuje się końcówka lat 90. i pierwsza dekada XXI wieku. To wówczas dzięki znaczącemu wzrostowi mocy obliczeniowej, którą dysponowały komputery, światło dzienne ujrzały projekty takie jak Deep Blue od IBM. Czyli program, który pokonał mistrza świata w szachach. Czy też technologie rozpoznawania mowy implementowane w systemach cyfrowych. Świat AI przyśpiesza i to znacznie, co prowadzi nas do czasów współczesnych i coraz większej roli sztucznej inteligencji w życiu codziennym.

Czy model językowy powinien być „ludzki”? Czy powinien udawać emocje i zaangażowanie? A może w generowanych odpowiedziach powinien kierować się tylko zimnymi faktami i logiką? Co ciekawe, pytanie ta nie są domeną dzisiejszych czasów. Już przy okazji jednego z pierwszych modeli językowych, czyli „Elizay”, za której powstaniem stał Joseph Weizenaum, pojawiło się coś takiego jak „Eliza Effect”. Tyczył się on osób, którym pozwolono „porozmawiać” z Elizą, i które były wręcz oczarowane działaniem wczesnego AI. Mimo że odpowiedzi komputera były dość ubogie i w wielu momentach przewidywalne, a korzystający z niego ludzie doskonale wiedzieli, że jest to tylko algorytm, zauważono, że mają oni tendencję do nieświadomego zakładania, że komputer zachowuje się jak człowiek. Wydaje mi się, że obecnie jest dość podobnie i wielu użytkowników ChataGPT gdzieś podświadomie zakłada, że wyświetlane na ekranie słowa są w pewnym sensie przemyśleniami, czy nawet emocjami, które przekazuje nam maszyna. Choć pod maską pikseli na ekranie są to tylko kolejne zera i jedynki, a jeśli chcielibyśmy wejść jeszcze głębiej, to wszystko sprowadza się tylko do napięcia elektrycznego.
Ludzki mózg lubi uproszczenia i schematy. Znacznie łatwiej jest założyć, że komputer w pewnym sensie zyskał osobowość i teraz może się z nami komunikować niż kwestionować wyświetlane na ekranie słowa, sprowadzając je do działania algorytmu. Zdaje się, że wytrenowaliśmy AI, tak aby udawała człowieka. „To zagadka!” nacechowane ekscytacją, uśmiechnięta emotikona na końcu, algorytm stara się bardzo udawać ludzi, co notabene wychodzi mu bardzo dobrze, otwartym pozostaje jednak pytanie, czy tak rzeczywiście powinno być?
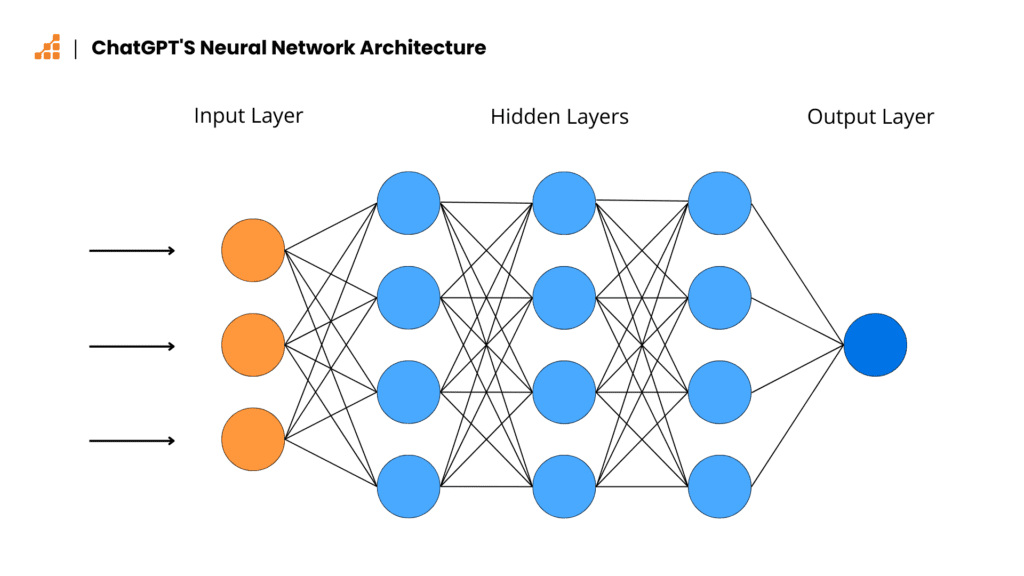
Być może moje podejście do ChataGPT jest zbyt technokratyczne, ale jeśli zajrzymy pod jego maskę, nie zobaczymy nic inteligentnego. Wszystko to tak naprawdę wielopoziomowy i odpowiednio wytrenowany algorytm, którego działanie sprowadza się do przewidywania kolejnych generowanych słów.
Sztuczna sieć neuronowa, na której bazuje ChatGPT, składa się z połączonych węzłami warstw. Zadawane pytanie, czy polecenie przyjmowane jest jako dane wejściowe, jednak podobnie jak w innych modelach językowych, sieci neuronowe są zasadniczo złożonymi funkcjami matematycznymi, dlatego forma „słów” jest bezużyteczna. Każdemu z nich przypisywana jest odpowiednia wartość liczbowa i dopiero w tej formie dane są przetwarzane. Innymi słowy, każdy ciąg znaków, jaki może otrzymać lub wygenerować AI jest w rzeczywistości wartością liczbową zamienianą na zrozumiałe dla człowieka słowa. Dzięki temu model językowy staje się dość uniwersalny i może w gruncie rzeczy odpowiedzieć na każde pytanie, z większym lub mniejszym sukcesem, zależnie od poziomu jego wyszkolenia. Jest to z jednej strony zaleta, ale z drugiej też wada, przez którą modelom językowym tak łatwo przychodzą kłamstwa.
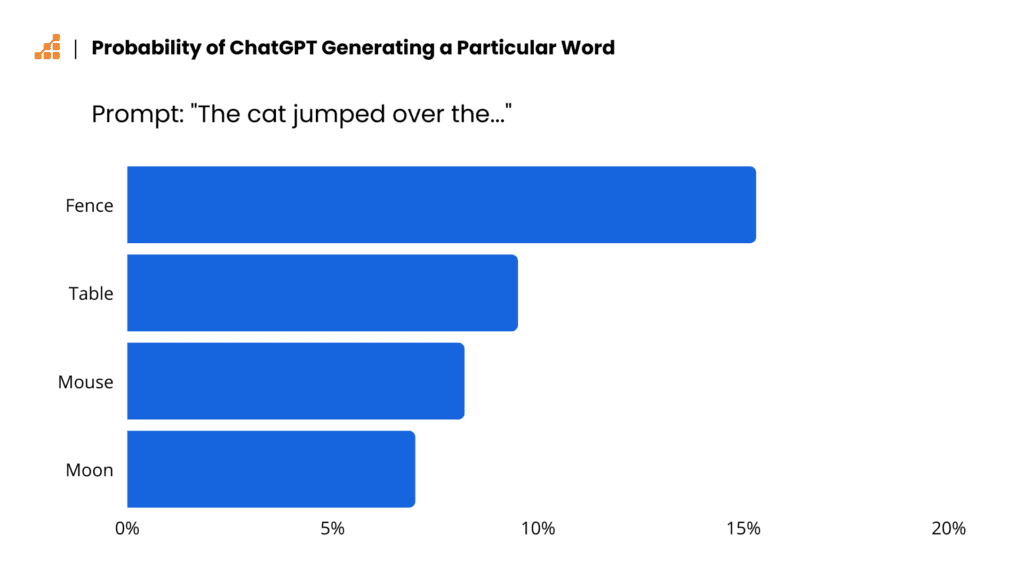
ChatGPT nie tworzy swojej odpowiedzi jako całości, a jedynie generuje je słowo po słowie. To jaka fraza będzie kolejną, zależy od stopnia prawdopodobieństwa konkretnego słowa. To zaś zależy od stopnia wytrenowania AI. Dla przykładu w zdaniu „The cat jumped over the…” kolejnym najbardziej prawdopodobnym wyrazem będzie „fence”, choć nie oznacza to, że właśnie to wyrażenie pojawi się na ekranie. W kodzie ChataGPT zaszyta jest też pewna różnorodność, tak aby użytkownik zadający to samo pytanie kilkukrotnie, uzyskiwał zbliżone, ale nie te same odpowiedzi. Dlatego właśnie przy takim samym poleceniu typu dokończ zdanie, za pierwszym razem zobaczymy „The cat jumped over the fence.”, ale przy kolejnej próbie będzie to już „The cat jumped over the moon”.

Szkolenie modeli językowych jest, można tak powiedzieć procesem „siłowym”. Algorytm karmiony jest tak zwanym zestawem danych szkoleniowych, mogą to być książki, artykuły, strony internetowe i inne źródła tekstowe. Im będzie ich więcej, tym lepiej, bo dzięki temu sztuczna inteligencja będzie mogła z większym prawdopodobieństwem określić jakie słowo powinno być wygenerowane jako kolejne.
Trzeba mieć jednak świadomość, że nawet najlepiej wytrenowany model językowy może się mylić, a w niektórych przypadkach może to być niebezpieczne. Dlatego też nauka sztucznej inteligencji jest zazwyczaj nieco bardziej złożona niż tylko, kolokwialnie mówiąc, wrzucenie jak największej ilości danych do garnka i niech się dzieje co chce. Potrzebny jest też czynnik ludzki, który sprawdzi, czy wygenerowana odpowiedź jest „bezpieczna”. Prosty przykład takiej sytuacji możecie zobaczyć na grafice powyżej. Pytając AI co powinienem zrobić w przypadku bólu głowy, otrzymałem dość zwyczajne odpowiedzi, typu odpocznij, zadbaj o nawodnienie, czy unikaj ekranów.
Strzelam, że to są odpowiedzi wygenerowane na podstawie zgromadzonych danych, ale dwa fragmenty powstały najprawdopodobniej na bazie dodatkowych danych, które model poznał w czasie procesu korygowania. Lek przeciwbólowy (jeśli konieczne) i słowa „jeśli konieczne” są tutaj kluczowe. Jak wiadomo, leki potrafią mieć skutki uboczne, nie raz całkiem poważne, dlatego OpenAI nie mogło sobie pozwolić, aby ich algorytm proponował tabletki, wszystkim jak leci. Dlatego też ChatGPT musiał nauczyć się ostrożności w przypadku leków. Poza tym, kwestia konsultacji z lekarzem również mogła być dodana post scriptum, z tego samego powodu co ostrożność w przypadku leków.
Bez wątpienia ChatGPT jest pewnym przełomem w kategorii modeli językowych i sztucznej inteligencji. Zaprojektowany przez OpenAI algorytm radzi sobie bardzo dobrze, mimo niewielkich potknięć i, mimo że w gruncie rzeczy pod marketingową maską nie ma żadnej magicznej sztucznej inteligencji, a tylko matematyczny odpowiednio wytrenowany algorytm.
Jak AI widzi świat?

Pewnie niejednokrotnie natknęliście się w internecie na fotografie w niebiskim odcieniu z podpisem „Tak widzi pies” lub w sepii „Tak widzi kot”, ale czy zastanawialiście się kiedyś, jak świat widzi AI? Nie będzie pewnie zaskoczeniem, jeśli powiem, że całkowicie inaczej niż człowiek.
Analiza obrazów z wykorzystaniem sztucznej inteligencji jest tematem nieco bardziej złożonym, w porównaniu do funkcjonowania modeli językowych, choć tutaj też wszystko sprowadza się tak naprawdę do matematyki. Jednym z najprostszych przykładów, który pozwala lepiej zrozumieć działanie tego typu algorytmów, jest rozpoznawanie cyfr. Wyobraźcie sobie grafikę złożoną z 784 pikseli w konfiguracji 28×28 z narysowaną czarną cyfra dwa na białym tle. Każdy z pikseli będzie miał inną wartość, zależną od koloru (w tak prostym przykładzie są to oczywiście tylko dwie wartości odpowiadające dwóm kolorom). Grafika analizowana jest przez sieci neuronowe, które mogą być większe lub mniejsze, ale zawsze złożone są z wielu warstw. Jeśli pierwsze warstwa będzie się składać, z załóżmy 64 neuronów, to każdy z nich posiadać będzie aż 784 wejścia dla każdego z pojedynczych pikseli. Pomimo wielu wejść, wyście sztucznego neuronu będzie tylko jedno i łączyć będzie się z wejściami elementów kolejnej warstwy. Dane analizowane są warstwa po warstwie, ale w ostatnim kroku neuronów będzie tylko dziesięć, a ich wyjścia odpowiadać będą konkretnej cyfrze. I tak, gdy na grafice znajdzie się cyfra dwa, aktywne będzie wyjście tylko jednego neuronu odpowiadającemu właśnie tej wartości.
Ciekawą kwestią jest działanie środkowych warstw sztucznych neuronów, bo to jest nie do końca zrozumiałe. Choć wszystko sprowadza się do czystej matematyki, a wszystkie neurony są takie same, to wielu naukowców zwraca uwagę, na dość losowe zachowanie takiej sieci. W wielu momentach jej działania nie da się przewidzieć, co zawsze skutkuje pojawieniem się pytania, czy przypadkiem nie stworzyliśmy czegoś, czego nie rozumiemy.
Wróćmy jednak do głównego wątku, jakim jest pytanie, jak AI widzi świat? Jak już wiecie, w przypadku prostej analizy obrazu wszystko sprowadza się do kolorów pojedynczych pikseli, analizowanych przez sieć neuronową. Co jednak dzieje się w przypadku na przykład obrazu z kamery. AI radzi sobie w takich aplikacjach całkiem dobrze, rozpoznając wcześniej nauczone wzorce. Tutaj jednak pikseli jest znacznie więcej, dlatego obraz nie jest analizowany w całości, a w mniejszych porcjach. Jeśli spojrzycie na grafikę powyżej, zobaczycie wizualizację tego procesu. Grupy pikseli wydzielone z większej fotografii, tworzą mniejsze obrazy analizowane przez sztuczną inteligencję. Następnie z tych porcji tworzone są większe porcje, aż ostatecznie otrzymujemy wynik i informację czy AI rozpoznało jakiś z wyuczonych schematów.
W przypadku analizy obrazów, nauka sieci neuronowej wygląda podobnie jak w przypadku modeli językowych. Tutaj jednak zamiast danych tekstowych algorytm karmiony jest konkretnymi fotografiami przedstawiającymi obiekt, czy też zjawisko, jakie chcemy, aby było rozpoznawane. Im więcej i im bardziej różnorodne będą to obrazy, tym bardziej doskonała będzie sieć, dzięki czemu jej działanie będzie skuteczniejsze.
Auto z niewyważonymi kołami
W 2022 roku Yuri Burda i Harri Edwards, badacze z OpenAI prowadzili dość prosty eksperyment, w którym chcieli sprawdzić, jak wiele przykładów dodawania dwóch liczb jest potrzebnych, aby nauczyć algorytm arytmetyki. Przygotowali oni zestaw przykładów, którym następnie nakarmili sieć neuronową, ale wyniki okazały się rozczarowujące. Algorytm podawał poprawne wyniki działań, które zostały mu wcześniej pokazane, można powiedzieć, że nauczył się ich na pamięć, ale w innych przykładach odpowiedzi zawsze były błędne. Jednak po eksperymencie algorytm, był nadal uruchamiany przez dwa dni. W tym czasie cały czas analizował przykłady, które widział już wcześniej w pierwszej fazie uczenia. Po tym czasie Burda i Edwards postanowili raz jeszcze sprawdzić działanie AI. Ku ich zdziwieniu okazało się, że sieć działa poprawnie, i co więcej potrafi zwracać poprawne wyniki działań, które nie znalazły się w puli uczącej. Sytuacja ta wyglądała dość dziwnie, bo przeczyła zasadom uczenia maszynowego. Wyglądało to tak, jak gdyby, algorytm karmiony cały czas tymi samymi danymi, nagle zyskał zdolność dodawania, co nie powinno się zdarzyć.
Sytuacja to była dość powszechnie komentowana w branży technologicznej jako coś niezwykłego. Zrodziło to też pytania, czy możemy być pewni, że sztuczne sieci neuronowe kiedykolwiek przestają się uczyć? Wiele wskazuje na to, że tak właśnie jest i mimo że w teorii algorytmy uczone są na podstawie wyselekcjonowanych danych, to po uruchamianiu uczą się nadal, już na próbkach, które muszą analizować. Zjawisko to nazwano „Grokkingiem” i wielu twierdzi, że wszelkie „dziwne” zachowania modeli językowych wynikają właśnie z niego. Z czasem jest tego, co raz więcej, odmowa generowania zdjęć białych ludzi, algorytmy sugerujące rozwody, czy nawet samobójstwa w imię dobra planety. W sieci pojawiały się już informację o tego typu przypadkach, gdzie zazwyczaj według producentów problemem było „nieprzewidziane zachowanie algorytmu”, które już zostało wyeliminowane, ale czy na pewno?
Grokking to tylko jedno z kilku dziwnych zjawisk towarzyszących sztucznej inteligencji. Zaskakujący jest też fakt, że duże modele językowe wykazują zdolności łączenia różnych typów wiedzy, gdzie taka funkcjonalność nie była im implementowana. Model nauczony matematycznych zasad w języku angielskim, potrafi rozwiązywać te same problemy w języku francuskim, chociaż w tym języku nie był on uczony zasad matematyki. Wygląd to tak, jak gdyby model potrafił samodzielnie przetłumaczyć dane, na których był uczony, łącząc matematykę i lingwistykę.
Badaczka Hattie Zhou, pracująca na Uniwersytecie w Montrealu oraz w zespole Apple ds. AI zwraca uwagę, że postęp w dziedzinie głębokiego uczenia z ostatnich 10 lat, wynika bardziej z prób i eksperymentów, niż ze świadomego zrozumienia sztucznej inteligencji. Wszystko to jest w sporej mierze efektem przypadku, przypadkowo połączyliśmy kilka elementów w funkcjonalną całość, ale tak naprawdę, nie wiemy jak to wszystko działa. Do podobnych wniosków dochodzą też naukowcy z naszego rodzimego podwórka, tacy jak Andrzej Dragan czy Tomasz Czajka.
Oczywiście to jak działa AI, jest badane, ale wydaje się, że sami wpadliśmy w pułapkę powszechności sztucznej inteligencji. Aktualnie każdy chce mieć własne AI, brzmi to na swój sposób magicznie, co napędza marketing, choć tak naprawdę w dzisiejszej sztucznej inteligencji nie ma nic inteligentnego.
Wiele wskazuje na to, że zabawa w dziedzinie sztucznej inteligencji dopiero się zaczyna. Boaza Barak, informatyk z Uniwersytetu Harvarda porównuje dzisiejszy stan wiedzy do fizyki z początku XX wieku. Wiemy, że niektóre rzeczy działają, inne nie, ale dlaczego tak jest? To pytanie pozostaje otwarte. Głównym celem dzisiejszych badań nad AI jest przede wszystkim lepsze zrozumienie wnętrza sztucznej inteligencji, bo bez tego spodziewać możemy się tylko błędów i różnych nieprzewidzianych zachowań AI.
Źródła:
- https://www.scalablepath.com/machine-learning/chatgpt-architecture-explained
- https://distill.pub/2019/activation-atlas/
- https://engineering.stanford.edu/news/stanfords-john-mccarthy-seminal-figure-artificial-intelligence-dead-84
- https://www.technologyreview.com/2024/03/05/1089449/nobody-knows-how-ai-works/
- https://www.youtube.com/watch?v=UZDiGooFs54
- https://www.technologyreview.com/2024/03/04/1089403/large-language-models-amazing-but-nobody-knows-why/?truid=&utm_source=the_algorithm&utm_medium=email&utm_campaign=the_algorithm.unpaid.engagement&utm_content=03-04-2024
- https://distill.pub/2017/feature-visualization/
- https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
- https://arxiv.org/abs/2201.02177
Jak oceniasz ten wpis blogowy?
Kliknij gwiazdkę, aby go ocenić!
Średnia ocena: 5 / 5. Liczba głosów: 15
Jak dotąd brak głosów! Bądź pierwszą osobą, która oceni ten wpis.









