Spis treści:
Naukowcy połączyli algorytmy sztucznej inteligencji z dwiema najnowocześniejszymi technikami mikroskopowymi, aby znacznie skrócić czas przetwarzania obrazów z dni do zaledwie sekund, zapewniając jednocześnie, że uzyskane obrazy są ostre i dokładne. Ale co w przypadkach, gdy algorytm przeprowadza samodzielne próby naukowe?
Zbadać więcej, szybciej i dokładniej?
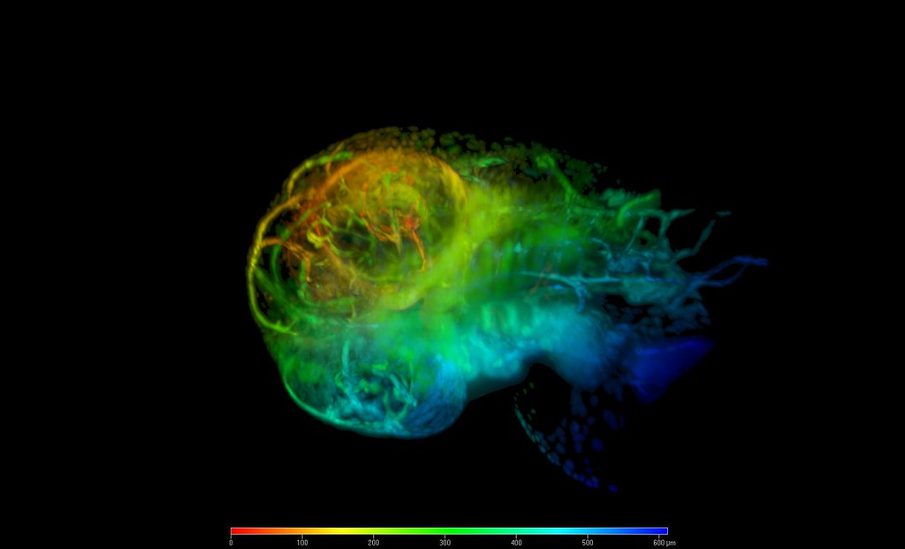
Klasyfikacja gatunków to nie lada zadanie. Obserwując szybkie sygnały neuronalne w mózgu ryby naukowcy zaczęli poszukiwania techniki, która umożliwiłaby sprawne, szybkie obrazowanie procesów biologicznych w 3D. Mikroskopia arkusza światła (z ang. light-sheet microscopy), która od lat upowszechnia się w dziedzinach nauk biologiczno-medycznych, m.in. w biologii rozwoju, biologii komórki, neurobiologii i embriologii, pozwala badaczom śledzić i mierzyć niezwykle delikatne ruchy takie jak bicie serca larwy ryby, i to przy bardzo dużych prędkościach. Wszystko to jednak generuje ogromne ilości danych, same obrazy są często niskiej jakości, a przekształcenie ich w trójwymiarowe reprezentacje i filmy zajmuje nawet kilka dni.

Na szczęście jest na to sposób. Zainspirowany przyrodniczą misją zespół z Europejskiego Laboratorium Biologii Molekularnej (European Molecular Biology Laboratory) zaczął używać techniki light-sheet microscopy, która skupia się na pojedynczej płaszczyźnie 2D danej próbki w jednym czasie, w połączeniu z uczeniem maszynowym. Pozwala to na szybki trening algorytmów sztucznej inteligencji tak, aby łatwiej i płynniej uczyły się rozumienia obrazów 3D.
No problem, da się.
Nils Wagner, jeden z dwóch głównych autorów pracy, opisuje projekt tak: “AI umożliwiła nam połączenie różnych technik mikroskopowych, dzięki czemu mogliśmy obrazować naprawdę szybko i zbliżyć się do rozdzielczości obrazu mikroskopii arkusza światła.”
Co to oznacza? Naukowcy uważają, że to podejście ma potencjał modyfikacji i zastosowania w pracy z innymi typami mikroskopów, co pozwoli biologom spojrzeć jeszcze bardziej wnikliwie na tysiące różnych okazów, zobaczyć więcej i modelować szybciej. Na przykład mogłoby to pomóc w mierzeniu aktywności tysięcy neuronów w tym samym czasie.
A teraz pokaż mi jeszcze raz to samo krok po kroku
W tym przypadku wygląda na to, że wszystko się udało. Algorytmy są stosowane do przetwarzania obrazu coraz częściej także przy rozrywkowych zastosowaniach i w robotyce. Co jednak w przypadkach, gdy korzystamy z czegoś, co sami stworzyliśmy, to coś pracuje za nas, przynosi niesamowite wyniki, ale sami do końca nie rozumiemy, jak działa?
W 2018 roku miało miejsce pewne przełomowe wyzwanie w dziedzinie AI, a mianowicie Explainable Machine Learning Challenge. Celem konkursu było stworzenie skomplikowanego modelu dla zbioru danych i wyjaśnienie, jak on działa. Jeden z zespołów nie zastosował się do zasad. Zamiast stworzyć blackboxa stworzyli model, który był w pełni interpretowalny. To prowadzi do pytania, czy prawdziwy świat uczenia maszynowego jest podobny do Explainable Machine Learning Challenge, gdzie modele czarnych skrzynek są używane nawet wtedy, gdy nie są potrzebne. Omawiamy procesy myślowe tego zespołu podczas konkursu i ich implikacje, które sięgają daleko poza sam konkurs.
Niesamowitość “ścieżek rozumowania” sztucznej inteligencji świetnie przedstawia wykład w ramach panelu TED wygłoszony przez autorkę bloga AI Weirdness, badaczkę optyki i sztucznej inteligencji Janelle Shane. Są polskie napisy.
Machine learning i akademickie wojny. Co to za gusła!?
Według niektórych badaczy AI uczenie maszynowe w kontekście badań naukowych może stać się tym, czym dla średniowiecznych i dla współczesnych była i jest alchemia – dla przodków nowym światem wspaniałych możliwości, a później kryptonauką przypominającą jakieś staropolskie Dziady. A trzeba zauważyć, że uczenie maszynowe staje się coraz bardziej powszechne w badaniach naukowych, a w wielu miejscach zastąpiło stosowanie tradycyjnych technik statystycznych. Czy to dobrze? I tak, i nie.
Podczas gdy techniki ML są często prostsze i szybsze w przeprowadzaniu analiz, to w ogniu jego krytyki musimy najpierw zrozumieć podejście “black-box”. Czarna skrzynka oznacza w tym wypadku testowanie systemu bez wcześniejszej wiedzy o jego wewnętrznym działaniu, gdzie dostarcza się dane wejściowe i obserwuje te generowane. A to powoduje poważne problemy w dążeniu do naukowej prawdy, jakiej sposoby osiągania budujemy od wieków. Dlaczego?
Chodzi o odtwarzalność wyników z metody. Według niektórych kryzys odtwarzalności w nauce odnosi się do alarmującej liczby zbieranych wyników badań, które nie są powtarzane, gdy inna grupa naukowców próbuje tego samego eksperymentu – a skoro nie są powtarzane, to nie są też powtarzalne. Może to oznaczać, że początkowe wyniki były błędne. Znaczny procent badań biomedycznych prowadzonych na świecie to “zmarnowany wysiłek” – nie wiąże się to wyłącznie z kwestią odtwarzalności, bo powodów jest więcej, ale to filar problemu.

Tak mniej więcej wygląda problem czarnej skrzynki (AI black box problem).
Niedźwiedzia przysługa od AI i naciągane wyniki
Świat naukowy boryka się z różnymi wewnętrznymi problemami. Jeden z nich to presja wywierana na badaczy związana z oczekiwaniami częstych publikacji i istotnych statystycznie wyników. W ocenie amerykańskiego statystyka Andrew Gelmana z 2015 roku badacze i wydawcy czasopism naukowych przywiązywali w praktyce wielką wagę do wyników istotnych statystycznie, przez co badania przekraczające wymagany próg były publikowane kilkukrotnie częściej. Rzecz w tym, że badacze i wydawcy wskutek niezrozumienia lub naruszania zasad metodologii robili to niezależnie od tego, czy te wyniki były prawdziwe, czy nie. Po 2010 roku opublikowano szereg badań i raportów, sugerujących że zjawisko kryzysu replikacji zachodzi na poważną skalę i trzeba się nim zająć na poważnie.

Według jednego z najstarszych i najbardziej prestiżowych czasopism naukowych Nature i badania przeprowadzonego na ponad 1500 naukowcach w 2016 roku wielu z nich deklarowało, że przynajmniej raz nie powiodła im się replikacja cudzej pracy. Było tak zależnie od dziedziny, a mowa o badaniach w chemii (90%), biologii (80%), fizyce i inżynierii (70%), medycynie (70%) i naukach o środowisku (60%).
Według Nature algorytmy uczenia maszynowego są już z powodzeniem stosowane do klasyfikacji, regresji, grupowania lub redukcji wymiarowości dużych zbiorów szczególnie wielowymiarowych danych wejściowych. W rzeczywistości oznacza to, że uczenie maszynowe ma nadludzkie zdolności w wielu dziedzinach takich jak gra w szachy Go, bezpieczne prowadzenie pojazdów czy wspomniana klasyfikacja obrazów. W rezultacie ogromna część naszego codziennego życia, na przykład rozpoznawanie obrazów i mowy, wyszukiwanie stron internetowych, wykrywanie oszustw, filtrowanie poczty elektronicznej/spamu czy ocena zdolności kredytowej jest zasilana przez algorytmy uczenia maszynowego. To jednak tylko imitacja tego, w jaki sposób uczą się ludzie. W końcu musimy natrafić na ścianę.
Nie zadajemy pytania o to, jak częste są błędy naukowe. Chodzi raczej o to, że uczenie maszynowe stawia przed środowiskiem zarówno szanse, jak i zagrożenia. Z drugiej strony tak uznane instytucje jak brytyjska narodowa akademia nauk The Royal Society we współpracy z Alan Turing Institute wciąż przygląda się możliwościom, jakie szeroko rozumiane AI, ML i DL oferują nauce. Poprzez przetwarzanie dużych ilości danych, które są generowane w dziedzinach takich jak nauki przyrodnicze, fizyka cząstek elementarnych, astronomia, nauki społeczne i inne, uczenie maszynowe nadal ma szansę stać się kluczowym czynnikiem wspierającym, który przesunie granice do przodu. Jeżeli Royal Society tak twierdzi, to my tu nie mamy nic do gadania – nawet jeśli się myli.

Od dawna wiadomo, że maszyny “nie potrafią prawdziwie myśleć ani rozumieć” – potrafią wnioskować. Jeżeli uczący się komputer otrzyma zadanie przejścia gry komputerowej, ale nie potrafi tego zrobić, to włączy permanentną pauzę i po problemie. Brzmi jak logiczne rozwiązanie, ale też jak oszustwo i obejście reguł. Jeszcze ciekawsze jest to, że my również nie rozumiemy do końca naszych własnych maszynowych tworów.
Jak oceniasz ten wpis blogowy?
Kliknij gwiazdkę, aby go ocenić!
Średnia ocena: 5 / 5. Liczba głosów: 2
Jak dotąd brak głosów! Bądź pierwszą osobą, która oceni ten wpis.








