Spis treści:
Co by nie mówić sztuczna inteligencja jest od dłuższego czasu poczytnym tematem. Co rusz w mainstreamowych mediach możemy zauważyć newsy o kolejnej przełomowej wersji ChataGPT, zawodach, które już za chwilę zostaną zastąpione przez AI, czy też rewolucyjnych funkcjach sztucznej inteligencji (przepraszam Apple Intelligence) w najnowszych Iphonach. Nic w tym dziwnego artykuły o AI są klikane, bo technologia ta budzi nie raz skrajne emocje. Jedni widzą w niej rozwiązanie wszystkich problemów ludzkości od ocieplenia klimatu po eliminacje chorób, z drugiej strony jednak we wielu ludziach AI budzi niepokój, głównie przez niezrozumienie jak działa ta technologia.


Schemat ten nie jest niczym nowym, podobnie zjawiska mogliśmy obserwować w przeszłości przy okazji rewolucji przemysłowej, czy też rozwoju elektryczności. Tak jak na początku XX wieku idący chodnikiem przechodnie mogli zobaczyć plakaty przeciwników elektryfikacji, tak w obecnych czasach możemy w internecie przeczytać opinie przeciwników sztucznej inteligencji. W mojej opinii zarówno głosy entuzjastów, jak i przeciwników AI powinniśmy „dzielić przez dwa”, bo jak mawia przysłowie „skrajności są złe”. Sztuczna inteligencja jest dla ludzkości szansą, może ona pomóc we wspomnianych między innymi badaniach nad chorobami i znacząco przyśpieszyć proces opracowywania nowych leków. Jednak należy pamiętać też o zagrożeniach, już teraz AI wspiera algorytmy, których zadaniem jest jak najdokładniej określić kolejne wyświetlane treści w popularnych socialmediach. O wpływie tak zwanego feedu na człowieka można by mówić wiele i długo, jednak niezależnie jakie badania weźmiemy pod uwagę, ich konkluzja będzie podobna, socialmedia uzależniają, a ich długotrwały wpływ na nasze umysły jest co najwyżej wątpliwy. Musimy zadać sobie pytanie, czy aby na pewno moce obliczeniowe sztucznej inteligencji powinny działać jako kolejny system zmieniający nas w przedstawicieli „homo ludens”, czyli ludzi, których celem jest tylko konsumpcja „treści” i zabawa.
Jednak co by nie mówić, wiadome jest tylko jedno, sztuczna inteligencja z nami zostanie, a jej znaczenie będzie z czasem tylko rosło. A naszym zadaniem jest tylko korzystać z niej z rozwagą i pamiętać o jej ciemnych stronach.
Matematyczne założenia

Idea sztucznej inteligencji nie jest niczym nowym, wszakże od wieków ludzie zastanawiali się, czy mogą istnieć istoty, a później i urządzenia „inteligentne” w ludzkim tego słowa znaczeniu. Sama inteligencja jest pojęciem, które możemy definiować w różnoraki sposób, najczęściej inteligencję określamy jako zdolność do przetwarzania informacji, analizowania ich i wyciągania logicznych wniosków. Jest to czysto ludzki sposób pojmowania, na który składają się cechy takie jak uczenie się, zdolności kognitywne, rozpoznawanie emocji czy też kreatywność. Poza tym wyróżnić możemy też inteligencję zwierzęcą, polegającą między innymi na zdolnościach adaptacji i zbiorową, gdzie indywidualne jednostki mają prostą strukturę zachowania, ale jako grupa osiągają złożone cele. Poza tym inteligencję możemy definiować w odniesieniu do technologii, wówczas mówimy o sztucznej inteligencji, która symuluje i stara się jak najwierniej odtworzyć aspekty ludzkiej inteligencji.
Choć temat sztucznej inteligencji poruszany był we wielu tekstach kultury to dopiero na przełomie lat 40. i 50. XX wieku naukowy świat zajął się nim na poważnie. Wówczas na scenie akademickiej pojawiło się pierwsze pokolenie naukowców zafascynowanych tym tematem. Jednym z nich był brytyjski erudyta Alan Turing, który zasugerował, że stworzenie czegoś, co moglibyśmy nazwać sztuczna inteligencją nie powinno wielce skomplikowane, wszakże „zadaniem rozumu jest tylko rozwiązywać problemy i podejmować decyzje, a w podobny sposób mogą działać także maszyny”. Trudno się nie zgodzić, że rozumowanie Turinga było genialne w swej prostocie, niedługo po sformułowaniu swoich tez wydał on w 1950 roku pracę zatytułowaną „Computing Machinery and Intelligence”, w której przedstawił niejako matematyczne założenia funkcjonowania sztucznego umysłu. Jednak choć na papierze wszystko wyglądało obiecująco, pojawił się dość duży problem – technologia.

Komputery przełomu lat 50. były drogie, skomplikowane, awaryjne, energochłonne i przede wszystkim ogromne, mogąc zajmować powierzchnię nawet dość sporego mieszkania. Poza tym nie dysponowały one jeszcze wystarczającą mocą obliczeniową, ale największym problemem była pamięć. Przed 1949 rokiem komputery jej nie miały, mogły one tylko wykonywać rozkazy zapisane na zewnętrznym nośniku, ale nie mogły ich zapamiętać. Innymi słowy, komputerom można było powiedzieć, co mają robić, ale nie mogły one pamiętać tego, co zrobiły.
Sukcesy i porażki
Choć Alan Turing przedstawił koncepcję, której ówcześnie nie dało się zrealizować, nie znaczyło to, że w przyszłości też tak będzie. Były to czasy galopującej technologii, pojawiających się co rusz nowinek, a także początku technologicznego wyścigu między USA i ZSRR. Gdy technika pędziła ku przyszłości, niejako w tle zorganizowane zostaje pierwsze sympozjum poświęcone idei sztucznej inteligencji, zainicjowane przez Allena Newella, Cliffa Shawa i Herberta Simona – Logic Theorist. Był to program finansowany przez Research and Development Corporation (RAND), którego celem było stworzenie miejsca do dyskusji na temat AI. Jednak mimo rozgłosu, konferencja nie spełniła oczekiwań większości naukowców, pomimo wielu paneli dyskusyjnych nie udało się osiągnąć porozumień w kwestii metod kontynuacji badań nad sztuczną inteligencją, ale co do jednego wszyscy byli zgodni – sztuczna inteligencja jest osiągalna, może nie dziś, nie jutro, ale rosnące znaczenie przemysłu komputerowego bez wątpienia spowoduje rozkwit AI.

I tak też właśnie było, od roku 1957 do 1974 sztuczna inteligencja kwitła. Komputery stawały się coraz bardziej złożone, a wraz z tym rosła ich moc obliczeniowa. Rosła pojemność pierwszych pamięci, a pojawienie się półprzewodników wróżyło wręcz nieograniczone możliwości. W podobnym tempie rozwijane były koncepcje sztucznej inteligencji. Pojawiły się pierwsze algorytmy uczenia maszynowego, sztuczne neurony oparte początkowo na lampach próżniowych, a także prowizoryczne modele językowe, takie jak „Eliza” zaprojektowana przez Josepha Weizenbauma. Z projektem tym wiąże się też ciekawa kwestia tak zwanego „Eliza Effect”, osoby, którym po raz pierwszy pozwolono „porozmawiać” z komputerowym modelem językowym, były wręcz oczarowane. Mimo że „Eliza” odpowiadała w dość przewidywalny i ubogi, jeśli chodzi o złożoność zdań sposób, zauważono, że większość osób miała tendencję do nieświadomego zakładania, że komputer zachowuje się jak człowiek. Jest to dość ciekawe, ponieważ wszyscy doskonale wiedzieli, że jest to tylko algorytm, kod realizowany przez krzemowe układy scalone. Jednak, gdy na ekranie pojawiała się niemal personalna wiadomość, sporo osób zakładało, że komputer przekazuje w ten sposób swoje „emocje” i „przemyślenia”, chodź pod maską zrozumiałych dla człowieka liter, kryły się wyłącznie zera i jedynki. Z przypisywaniem ludzkich cech maszynom możemy spotkać się także dziś, jednak powszechna globalizacja i dostęp do technologicznych nowości sprawił, że jest to niezwykle rzadkie i raczej przechodząc przez automatycznie otwierające się drzwi galerii, nie usłyszymy „Dziękuję Panie Darku”.
W projekty AI angażował się też amerykański rząd, powołana do życia Agencja Zaawansowanych Projektów Badawczych Obrony (DARPA) zainteresowana był przede wszystkim maszyną, która umożliwiałaby transkrypcję i tłumaczenie języka mówionego w czasie rzeczywistym oraz algorytmami służącymi do bardzo szybkiego przetwarzania danych. Optymizm był wielki, a oczekiwania jeszcze większe. W 1970 roku na łamach na łamach Life Magazine, Marvin Minsky jeden z naukowców zajmujących się sztuczną inteligencją wróżył, że „Za trzy do ośmiu lat powstaną maszyny tak inteligentne, jak przeciętny człowiek”. Jednak i tym razem przeszkodą okazała się technologia.

Mimo że rozwijała się ona z dnia na dzień, to rozwój teorii AI był jeszcze szybszy. Nadal brakowało mocy obliczeniowej, aby uruchomić przygotowane teoretycznie algorytmy, poza tym przetwarzanie mowy, które rozpalało umysły wielu naukowców, wymagało olbrzymich ilości pamięci, której w tamtym czasie po prostu nie było. Lata dobrobytu dobiegły końca, wycofało się wielu inwestorów i powszechną opinią stały się słowa Johna McCarthy’ego – „Komputery są nadal milion razy za słabe, aby wykazać się inteligencją”. Na nic zdały się osiągnięcia lat 80., opisane po raz pierwszy techniki uczenia głębokiego (deep lerning) czy też tak zwany program „ekspercki”, czyli algorytm, który potrafił zapamiętywać informację z określonej dziedziny pozyskiwane od odpowiedniego eksperta i na ich podstawie odpowiadać na zadawane pytania.
Jak na ironię, przy braku funduszy i większego publicznego szumu sztuczna inteligencja rozwinęła się jak nigdy wcześniej. Proces ten możemy obserwować od końca lat 90., w 1997 roku ówczesny mistrz szachowy zostaje pokonany przez Deep Blue, czyli przygotowany przez IBM program komputerowy. W tym samym roku integralną częścią systemu Windows staje się oprogramowanie do rozpoznawania mowy przygotowane przez Dragon Systems. Ograniczenia mocy obliczeniowej i pamięci, które wstrzymywały rozwój AI przez około 30 lat, okazały się problemem drugorzędnym i od tego czasu obserwować możemy kolejny historyczny rozkwit sztucznej inteligencji.
Jak działają sztuczne sieci neuronowe?
Sztuczne sieci neuronowe są aktualnie dość skomplikowanymi tworami, a powiedzieć można nawet, że w pewnych aspektach przestaliśmy rozumieć sposoby działania AI, ale o tym później. Jednak nic nie stoi na przeszkodzie, aby przyjrzeć się bliżej pojedynczemu elementowi, na którym bazowane są dzisiejsze sieci neuronowe.
Sztuczna inteligencja stara się naśladować sposób, w jaki działa ludzki mózg i tak jak mózg oparty jest między innymi na neuronach, tak i AI oparta została na sztucznych neuronach, nazywanych też perceptronami. Koncepcja tego typu elementu „decyzyjnego” nie jest niczym nowym, jego teoretyczne opisy pojawiły się już w pierwszej fazie rozwoju sztucznej inteligencji. Początkowo neurony budowano fizycznie, przykład takiego urządzenia zaprojektowanego przez Marvina Minskyego mogliście zobaczyć na jednej z wcześniejszych grafik. My jednak zajmiemy się teoretycznym konceptem, bo jest on na swój sposób fascynujący, a niezwykłe jest to, że nawet jego graficzne przedstawienie przypomina biologiczny neuron.
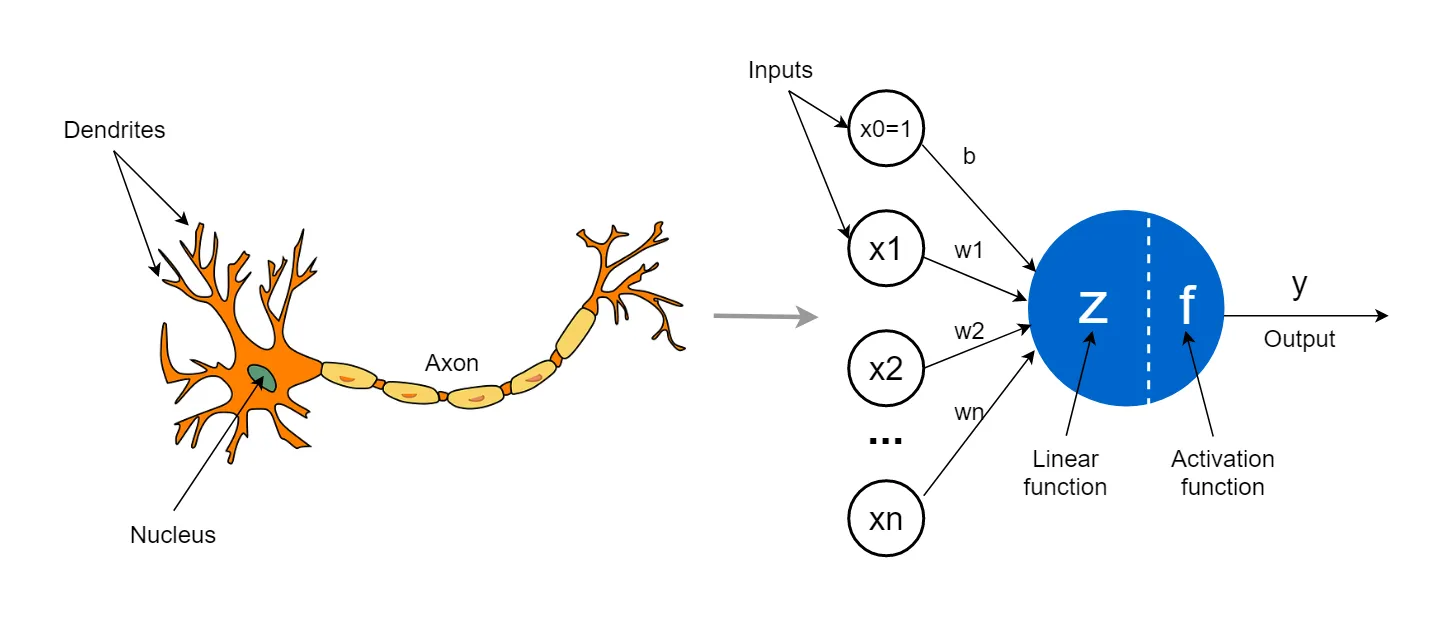
Perceptron możemy wyobrazić sobie jako niewielki element o wielu wejściach i pojedynczym wyjściu. Poprzez wejścia sztuczny neuron otrzymuje informacje, zapisane w formie matematycznej symbolizujące dla przykładu wzrost, wagę oraz wiek człowieka. Neuron nie traktuje wszystkich informacji tak samo, dane są hierarchiczne i niektóre są ważniejsze od innych. Dlatego każda informacja jest „ważona”, czyli mnożona przez specjalną liczbę zwaną wagą. Działa to w podobny sposób jak wagi ocen znane ze szkoły. Dla przykładu, gdyby zadaniem neuronu było przewidywanie stanu zdrowia informacje takie jak waga i wiek byłyby ważniejsze niż wzrost i mnożone byłyby przez odpowiednio większą wartość.
Wstępnie obrobione dane są następnie sumowane, a do wyniku dodawana jest jeszcze niewielka liczba zwana „biasem”, działa ona jak poprawka pozwalająca neuronowi zachowywać się nieco bardziej elastycznie. Otrzymany wynik definiuje ostateczną decyzję. W prostych przykładach ogranicza się to zazwyczaj do liczb dodatnich i ujemnych. W przykładzie, gdzie neuron przewiduje stan zdrowia, można by powiedzieć, że gdy wynik jest większy od zera, prawdopodobnie dana osoba cieszy się dobrym zdrowiem, a przy wartości mniejszej od zera prawdopodobieństwo problemów zdrowotnych jest większe.
Być może zastanawiacie się w jaki sposób neuron „decyduje”, czy wszystko to jest zasługa cudownej matematyki, przemnożenia kilku liczb i ich zsumowania? Odpowiedź to i tak i nie, można powiedzieć, że cała magia działania sztucznych sieci neuronowych realizowana jest poprzez proces ich uczenia. Początkowo każdy neuron musi otrzymać surowe dane wraz z wynikiem, tak aby mógł on nauczyć się „przewidywać”. Działa to w ten sposób, że informacje przekazywane są w kolejnych paczkach, a modyfikowana jest wartość wag i poprawki, tak aby na wyjściu uzyskać poprawny wynik. Wyćwiczona w ten sposób sieć po przeanalizowaniu odpowiedniej ilości przykładów, będzie potrafiła reagować na nowe dane i z dużą dozą prawdopodobieństwa przewidywać poprawny wynik.
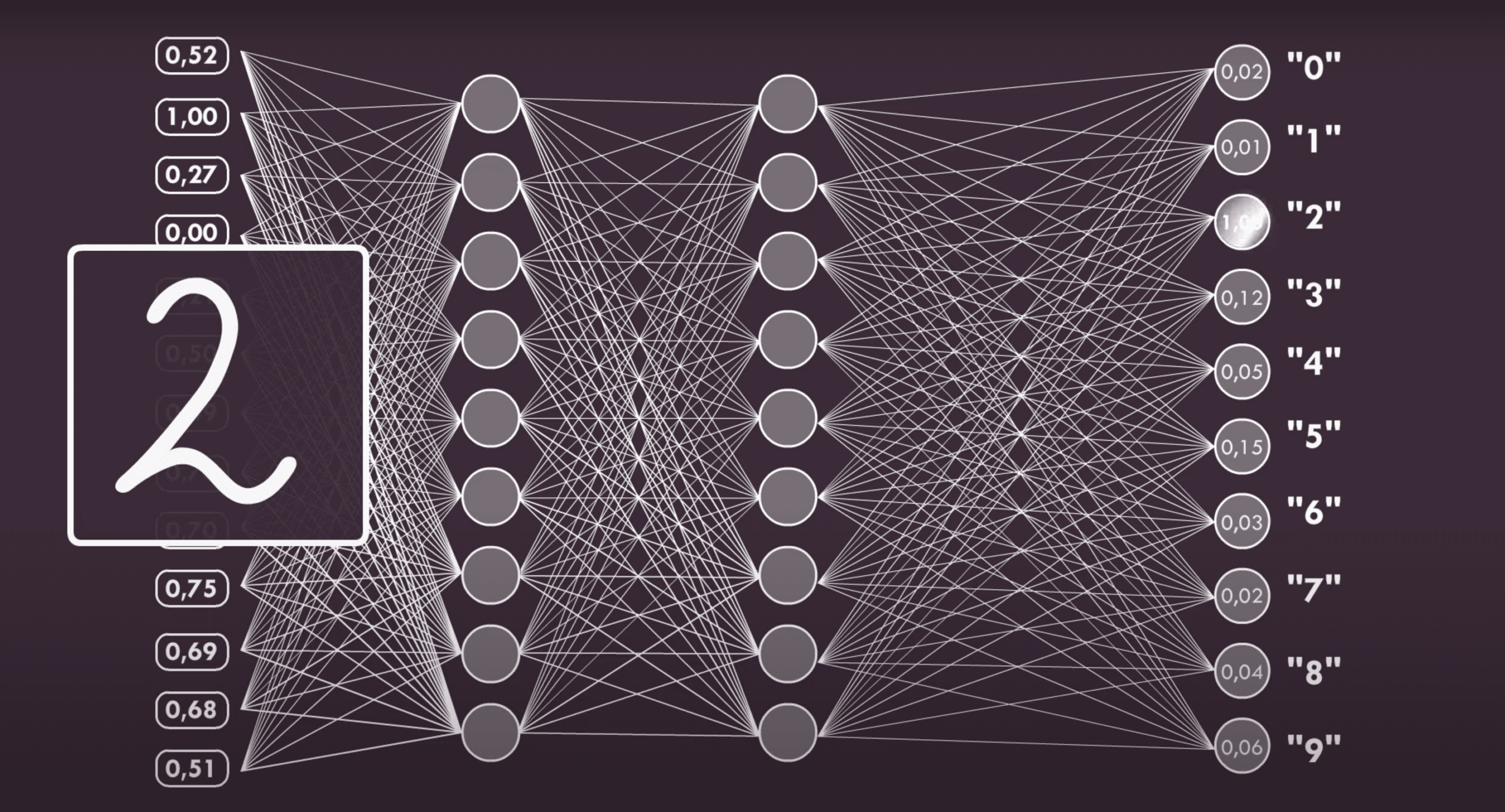
Sztuczne sieci neuronowe potrafią być naprawdę ogromne. Dość popularnym przykładem jest pojawiająca się w opracowaniach na temat AI sieć analizująca obraz założony z 784 pikseli w konfiguracji 28×28. Jej zadaniem jest rozpoznawać narysowaną odręcznie na tym obszarze cyfrę. Każdy piksel ma inną wartość, która zależna jest od faktu czy piksel jest ciemniejszy bądź jaśniejszy (poruszamy się tylko w spektrum szarości, od koloru białego do czarnego). Sieci neuronowe budowane są też warstwowo i dla przykładu, jeśli pierwszy poziom składa się z 32 neuronów, to każdy z nich ma 784 wejścia odpowiadające każdemu pikselowi. W kolejnych warstwach neuronów może być więcej lub mniej, ale na ostatnim poziomie będzie ich dziesięć, z których każdy przypisany będzie do innej cyfry i otrzymywane na ich wyjściu wyniki odpowiadać będą decyzji na zasadzie „narysowane jest zero” lub „nienarysowane jest zero”.
Środkowych warstw neuronów może być również całkiem sporo, zasadniczo im jest ich więcej, tym dłużej będzie trwać proces uczenia się sieci, ale będzie ona też dokładniejsza, a jej przewidywania bliższe rzeczywistości. Ciekawym aspektem jest, fakt, że działanie wewnętrznych warstw, które nazywane są warstwami ukrytymi, jest nie do końca zrozumiała. Choć jest to matematyka w czystej postaci, a wszystkie neurony są takie same, to wielu badaczy AI poddaje pod wątpliwość zrozumienie ich działania. Twierdzą oni, że samoucząca się sieć, zachowuje się dość losowo i zachowania tego, w gruncie rzeczy nie da się przewidzieć, co w dość oczywisty sposób owocuje tezą, że stworzyliśmy coś, czego nie rozumiemy.
Nieograniczone możliwości, czyżby?

Jakiś czas temu swoją premierę miał oficjalny moduł AI współpracujący z mikrokomputerem Raspberry Pi 5. Niewielkie urządzenie wykorzystujące nakładkę M.2 łączone jest z procesorem RPI poprzez magistralę PCIe, odciążając tym samym procesor w obliczeniach związanych ze sztuczną inteligencją. Podobnie jak koprocesor Hailo wspomaga jednostkę centralną Raspberry Pi 5, tak samo inteligentny sensor Sony IMX500 potrafi przetwarzać obraz w oparciu o sieci neuronowe. Jest on elementem składowym dedykowanej dla RPI kamery AI, która swoją premierę również miała nie tak dawno. Nasuwa się jednak pytanie, dlaczego tak nagle pojawiać zaczęły się akcesoria dla popularnego mikrokontrolera związane ze sztuczną inteligencją? Czyżby główny procesor malinki nie radził sobie z AI? Jednak jak to zwykle bywa, odpowiedź nie jest w pełni jednoznaczna.
Raspberry Pi 5 jak na swoje niewielkie rozmiary i pobór energii radzi sobie całkiem nieźle ze sztucznymi sieciami neuronowymi, ale wydajność zawsze mogłaby być większa. Dlatego właśnie powstają specjalne moduły wyposażone w chipy dedykowane do obliczeń związanych ze sztuczną inteligencją. Sytuacja ta dość dobrze obrazuje obecną sytuację w świecie AI. Ta rozwija się całkiem prężnie, ale jej wydajność na koniec dnia będzie równa wydajności najlepszych chipów Nvidii.
Tradycyjne procesory stosowane w komputerach osobistych, nie są najlepszym wyborem w aplikacjach związanych ze sztuczną inteligencją, ponieważ nie radzą sobie najlepiej w równoległych obliczeniach na dużą skalę, a tym w gruncie rzeczy jest AI. Dlatego do tego celu wykorzystywane są przede wszystkim układy graficzne Nvidii. Konstrukcje te oparto na niewielkich rdzeniach, których jest relatywnie dużo w porównaniu do klasycznych procesorów, które mają zazwyczaj kilka, kilkanaście rdzeni. Proste jednostki obliczeniowe sprawdzają się w procesie generowania grafiki, ponieważ opiera się ona na wielu identycznych obliczeniach, wszakże każdy piksel musi być osobno wygenerowany. W czasie badań nad sztuczną inteligencją okazał się, że GPU nadają się także do obsługi sztucznych sieci neuronowych.
Jednakże nawet nowoczesne procesory graficzne, mimo swojej wydajności, nie są idealnym rozwiązaniem. Ich pierwotnym przeznaczeniem jest przetwarzanie grafiki i choć radzą sobie dobrze w obliczeniach związanych z AI, to ich architektura nie jest perfekcyjnie dostoswana do tego typu zadań. Stąd możemy obserwować, na razie dość powolne pojawianie się specjalizowanych układów ASCI (Application-Specific Integrated Circuits) lub jednostek TPU (Tensor Processing Units), które szyte są na miarę potrzeb AI. Można wróżyć, że w przyszłości tego typu konstrukcji będzie tylko więcej. Poza tym nie jest wykluczone, że rozwój sztucznej inteligencji wymusi powstanie czegoś zupełnie nowego, czego do tej pory jeszcze nie widzieliśmy, a co będzie zdecydowanie dominować w świecie AI.
Po raz kolejny okazuje się, że technologia jest pewnym ograniczeniem dla sztucznej inteligencji i mimo że jej obecne tempo rozwoju jest naprawdę imponujące, to któregoś dnia może się okazać, że hardware nie nadąża za softwarem.
Źródła:
- https://pivotal.digital/insights/1936-alan-turing-the-turing-machine
- https://chauhaninfocom.wordpress.com/tag/history-of-computer-technology/
- https://sitn.hms.harvard.edu/flash/2017/history-artificial-intelligence/
- https://zahid-parvez.medium.com/history-of-ai-the-first-neural-network-computer-marvin-minsky-231c8bd58409
- https://www.nytimes.com/2016/01/26/business/marvin-minsky-pioneer-in-artificial-intelligence-dies-at-88.html
- https://towardsdatascience.com/the-concept-of-artificial-neurons-perceptrons-in-neural-networks-fab22249cbfc
Jak oceniasz ten wpis blogowy?
Kliknij gwiazdkę, aby go ocenić!
Średnia ocena: 4.9 / 5. Liczba głosów: 16
Jak dotąd brak głosów! Bądź pierwszą osobą, która oceni ten wpis.










